
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/2023-12-01-Export-Posts-Text-Master.csv')Text Classification
The text as data chapter introduced us to the idea that text is unstructured data. To make it useful for quantitative analyses, we need to process it into measurable structured data, which allows for systematic analysis and comparison. This process is for many analyses the operationalization step, where we translate theoretical concepts into measurable quantities (Nguyen et al. 2020). Content analysis, a research method used in social science and other disciplines, provides a well-established framework for all necessary steps towards operationalization, classification (labelling or coding), and evaluation. Content analysis can be conducted qualitatively and quantitatively. Döring and Bortz (2016) define the two as:
“Typical for qualitative document analyses is a research problem that presents itself as an open research question and thus has an explorative or theory-building function; accordingly, the entire procedure - despite a reference to the previous state of research and the use of a theoretical framework - is rather inductive, i.e. data-driven.” – (Döring and Bortz 2016, 540)
“[…] a quantitative content analysis must first be carried out in order to generate measured values. In contrast to qualitative document analysis, which interprets a small number of documents in detail, quantitative document analysis works with much larger […] samples of documents. The documents are analysed against the background of the respective research problem with regard to individual, theoretically relevant quantitative characteristics.” – (Döring and Bortz 2016, 552)
Last session’s text exploration approaches might be useful in context of qualitative document analyses, especially for identifying emerging themes or patterns within a smaller set of documents. For example, text exploration can help us uncover initial categories or concepts that can then be examined in detail through qualitative methods. For the quantitative approach, however, we need to operationalize our concept of interest (from the theory, or we use operationalization from the literature), and classify our text according to the operationalization. Additionally, we want to evaluate the computational classification, which will be next session’s topic. For today’s session, we work with two operationalizations, or measurements, from the literature: 1) Mobilization (Wurst, Pohl, and Haßler 2023; Haßler, Kümpel, and Keller 2021), and 2) Sentiment (Møller et al. 2023; Schmidt et al. 2022).
Classification using GPT
We are going to practice text classification using GPT based on operationalization from the literature. As outlined above, we are going to measure sentiment and mobilization. Each variable has different values and applications:
Sentiment analysis, also known as Opinion Mining, is a field within natural language processing (NLP) and linguistics that focuses on identifying and analyzing people’s opinions, sentiments, evaluations, appraisals, attitudes, and emotions expressed towards various entities like products, services, organizations, individuals, events, and topics (B. Liu 2022). Generally, we can conduct polarity-based and emotion-based sentiment analyses. In today’s session we are interested in polarity: Schmidt et al. (2022) distinguish between Positive, Negative, Neutral, and Mixed tweets, Møller et al. (2023) use the categories Positive, Negative, and Neutral.
Mobilization, on the other hand, refers to the efforts made by political parties to encourage and activate citizens to participate in the political process. This can include activities such as voting, supporting a campaign, seeking political information, liking and sharing posts on social media, and other forms of civic engagement (Wurst, Pohl, and Haßler 2023). The authors distinguish between three types of calls to participate: calls to inform, calls to interact, and calls to support. They also subcategorized offline and online forms of each type of call.
Tip
In the next chapter, we fine-tune a BERT model for text classification.
Prompt Engineering
PPrompt engineering is a new technique in machine learning that has grown alongside the development of large pre-trained models, such as foundation models or large language models (LLMs). Foundation models are extensive, pre-trained neural networks that serve as a base for a wide range of downstream tasks, providing a flexible framework for different applications. This method emerged when it was realized that these models work better with well-designed inputs. Prompt engineering is about creating or changing a question or input so the model can more easily find the right information (Gu et al. 2023). It is based on the understanding that different questions can produce more or less accurate results, so adjusting the format and examples of the prompt is key to getting the best results (Zhao et al. 2021). The field of prompt engineering involves different ways of making these prompts. One can decide to create prompts manually or use automated methods (P. Liu et al. 2023). The growth and use of prompt engineering signify a major change in machine learning, deeply linked to the flexibility and wide range of applications of foundation models (Gu et al. 2023).
According to Törnberg (2024), prompt engineering for text annotation tasks using LLMs requires several important steps to ensure effective prompt engineering for text annotation tasks using LLMs. First, it is important to choose an appropriate model, considering factors such as reproducibility, ethics, transparency, and the complexity of the task. Next, Törnberg suggests following a systematic coding procedure that involves iterative rounds of calibration between human coders and LLM outputs to ensure consistency and alignment. He emphasizes that a prompt codebook should be developed to serve as a detailed guide for both human and machine annotation, ensuring replicability and reducing ambiguity. Furthermore, Törnberg highlights the importance of prompt stability analysis, which involves testing prompts systematically to ensure that small changes do not lead to significant variations in model responses. This systematic testing is crucial, as it helps to avoid overgeneralizations and ensures robustness across a variety of contexts. Zamfirescu-Pereira et al. (2023) add that non-experts often fail to systematically test prompts, which can create a false sense of reliability when only tested on a few cases.
Zero-Shot Classification
Zero-shot prompting is a method where a model receives only a natural language instruction to perform a task, without any prior examples or demonstrations, which mirrors the way humans often approach tasks, using only textual instructions. This approach emphasizes convenience and the potential for robustness, minimizing the risk of learning spurious correlations that may be present in the training data. However, this method presents significant challenges, as it can be hard even for humans to understand the task requirements without examples (Brown et al. 2020).
Designing the Prompt
The literature provides several prompts for sentiment analysis using GPT-models. The Prompt Compass (Borra, n.d.) and Can Large Language Models Transform Computational Social Science? (Ziems et al. 2024) are good strating points for ideas and prompts for social science applications. For our tutorial, let’s use this example:
System prompt: You are an advanced classifying AI. You are tasked with classifying the sentiment of a text. Sentiment can be either positive , negative or neutral.
Prompt: Classify the following social media comment into either ‘negative’, ‘neutral’ or ‘positive’. Your answer MUST be either one of [‘negative’, ‘neutral’, ‘positive’]. Your answer must be lowercase.
Note
- System Prompts: These are instructions that define the general behavior of the model. They set the context for how the LLM should respond, such as defining its role as a classifying AI. The system prompt establishes the model’s identity, expertise level, and provides guidelines to direct its overall actions.
- Prompts: These are user-provided instructions for a specific task, like classifying the sentiment of a given text. Prompts are the detailed commands or queries that the model must respond to, with specific expectations for the output format. Prompts can vary greatly depending on the specific analysis or outcome required.
- See e.g. http://promptingguide.ai for advice on prompt design and techinques.
- Use the OpenAI Playground for testing.
Testing new prompts in the ChatGPT interface proved useful in my experiments, providing an initial evaluation of prompt efficacy without additional cost. The following screenshot shows the sentiment analysis prompt used with some random Amazon reviews:
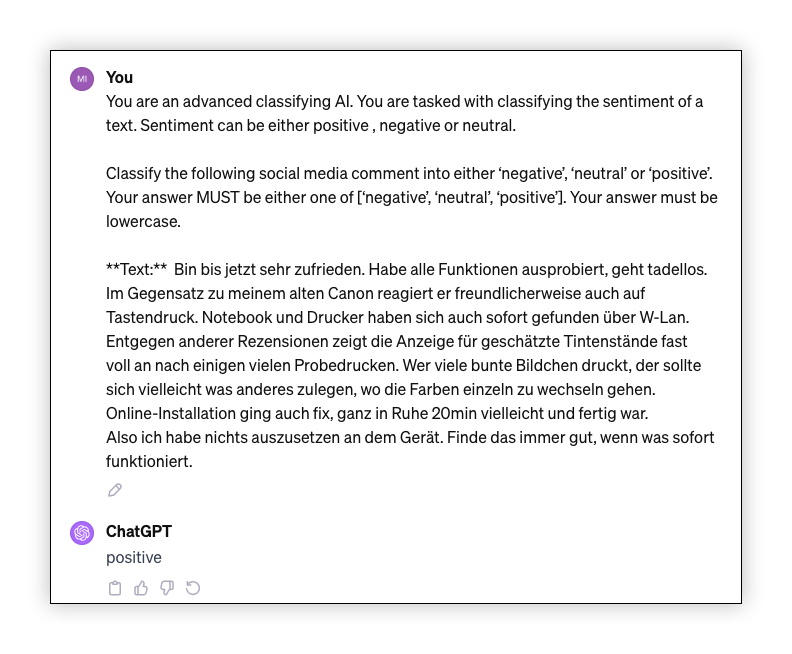
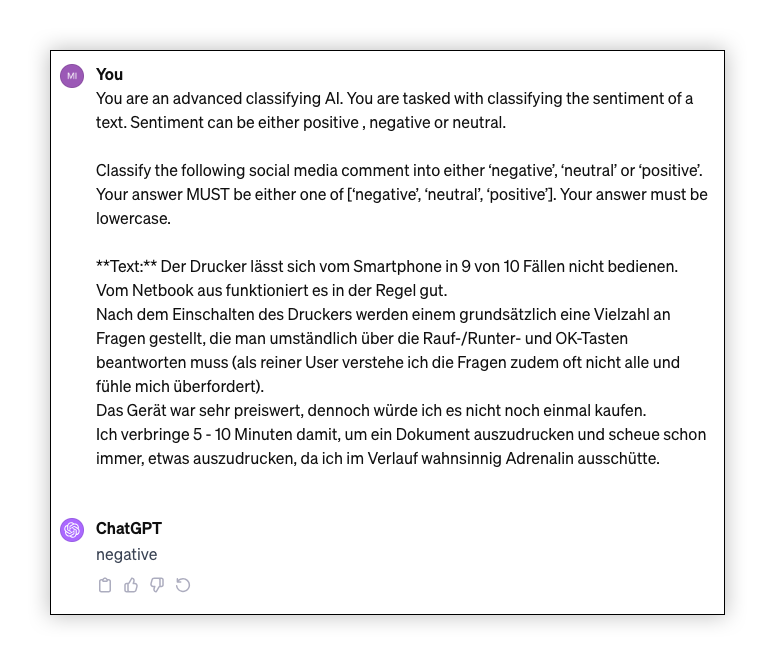
Warning
Be mindful of the pitfalls outlined by Zamfirescu-Pereira et al. (2023), especially the risk of overgeneralizing from a limited number of successful classifications. To ensure robustness, prompts should be systematically tested across diverse examples and contexts.
Using the ChatGPT interface, we can also interact with the model asking for updates:
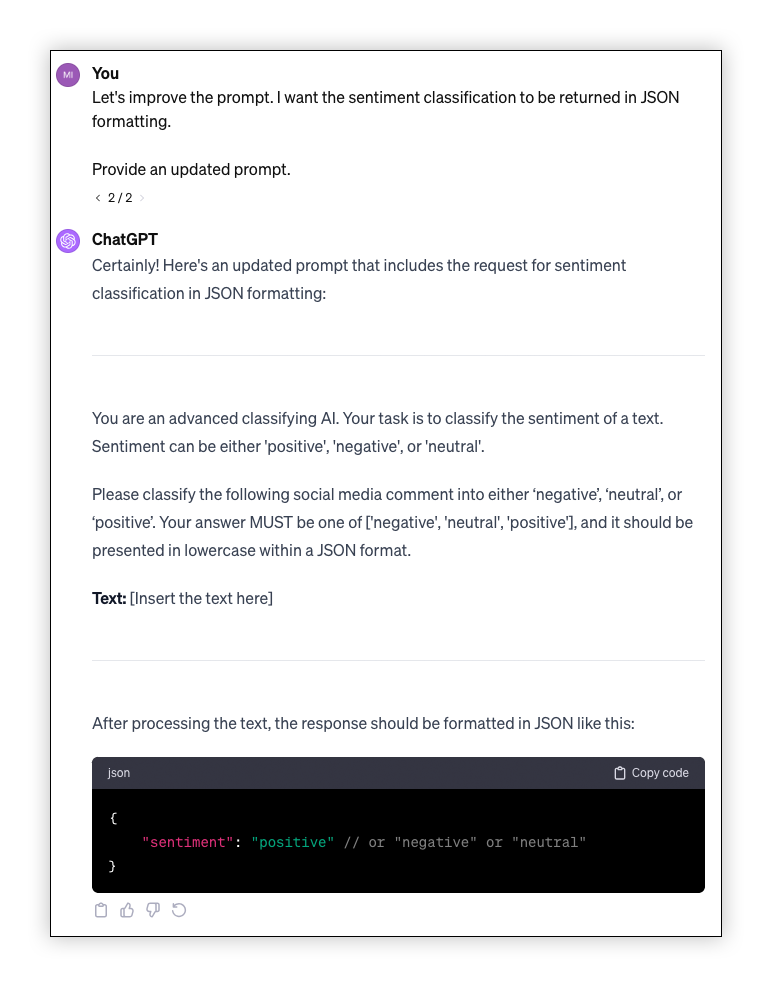
System Prompt: You are an advanced classifying AI. Your task is to classify the sentiment of a text. Sentiment can be either ‘positive’, ‘negative’, or ‘neutral’.
Formatting: After processing the text, the response should be formatted in JSON like this:
{ "sentiment": "positive" // or "negative" or "neutral"` }Please classify the following social media comment into either ‘negative’, ‘neutral’, or ‘positive’. Your answer MUST be one of [‘negative’, ‘neutral’, ‘positive’], and it should be presented in lowercase within a JSON format.
Text: [Insert the text here]
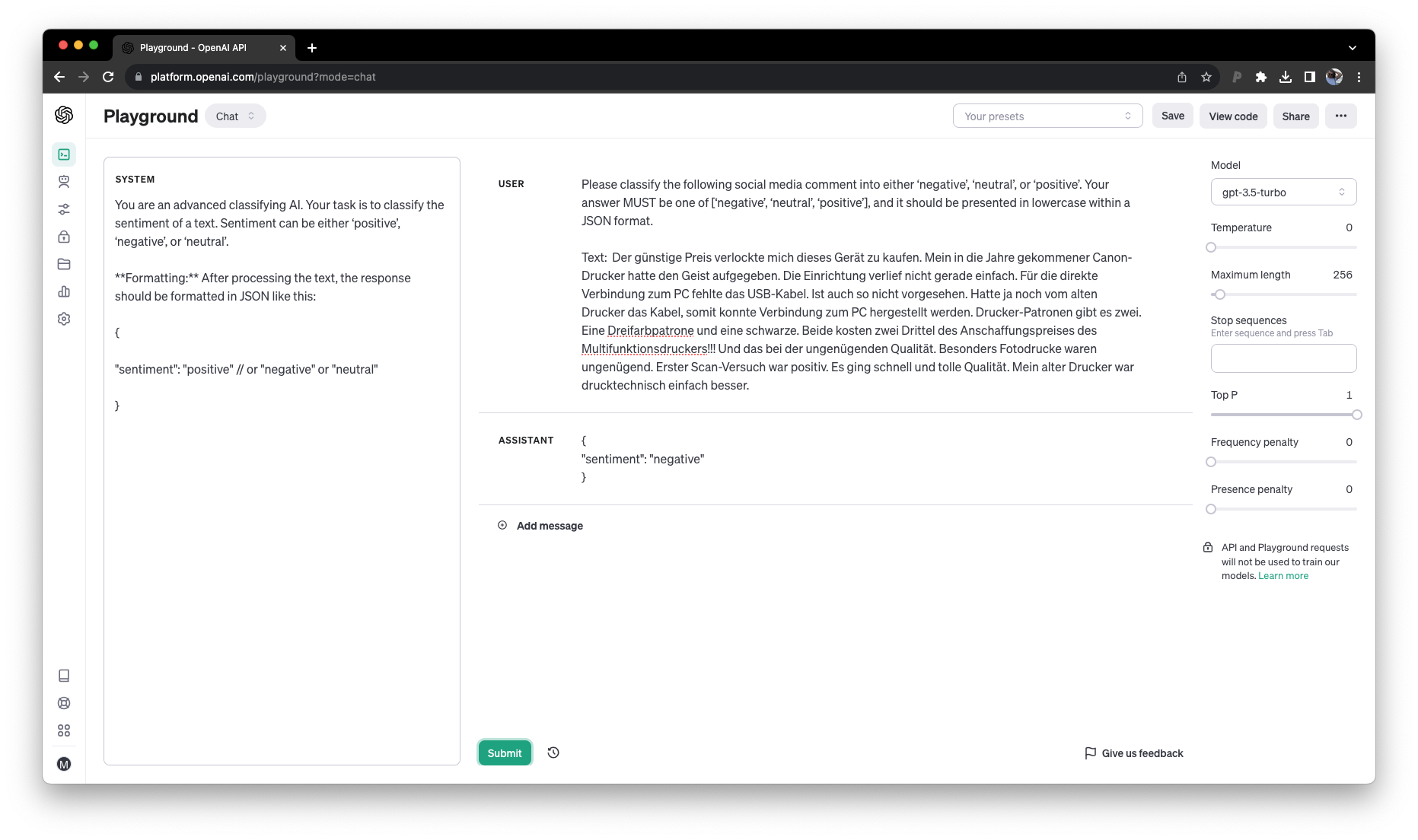
Next, let’s use our improved prompt in the playground to test the differntiation between system prompt and user prompt:
Tip
Set the temperature variable to 0 for more consistent model output.
Implementing the Prompt using Python
TipUpdate Winter 2024/25 🚀
I updated the GPT Text Classification Notebook: * Removed the multidocument classification approach. * Added a new section that makes use of Structured Outputs. * Added another few-shot approach: Using multiple user and system messages. * Updated the models to the new GPT-4o generation.
GPT Text Classification
Let’s read last week’s Text DataFrame
df.head()| Unnamed: 0 | shortcode | Text | Text Type | Policy Issues | |
|---|---|---|---|---|---|
| 0 | 0 | CyMAe_tufcR | #Landtagswahl23 🤩🧡🙏 #FREIEWÄHLER #Aiwanger #Da... | Caption | ['1. Political parties:\n- FREIEWÄHLER\n- Aiwa... |
| 1 | 1 | CyL975vouHU | Die Landtagswahl war für uns als Liberale hart... | Caption | ['Landtagswahl'] |
| 2 | 2 | CyL8GWWJmci | Nach einem starken Wahlkampf ein verdientes Er... | Caption | ['1. Wahlkampf und Wahlergebnis:\n- Wahlkampf\... |
| 3 | 3 | CyL7wyJtTV5 | So viele Menschen am Odeonsplatz heute mit ein... | Caption | ['Israel', 'Terrorismus', 'Hamas', 'Entwicklun... |
| 4 | 4 | CyLxwHuvR4Y | Herzlichen Glückwunsch zu diesem grandiosen Wa... | Caption | ['1. Wahlsieg und Parlamentseinstieg\n- Wahlsi... |
Setup for GPT
!pip install -q openai backoff gpt-cost-estimator━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 221.4/221.4 kB 3.2 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 75.0/75.0 kB 7.9 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.0/2.0 MB 12.1 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 76.9/76.9 kB 7.8 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 58.3/58.3 kB 6.2 MB/s eta 0:00:00 ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. llmx 0.0.15a0 requires cohere, which is not installed.
We’re using the new Colab Feature to store keys safely within the Colab Environment. Click on the key on the left to add your API key and enable it for this notebook. Enter the name of your API-Key in the api_key_name variable.
import openai
from openai import OpenAI
from google.colab import userdata
import backoff
from gpt_cost_estimator import CostEstimator
api_key_name = "openai-lehrstuhl-api"
api_key = userdata.get(api_key_name)
# Initialize OpenAI using the key
client = OpenAI(
api_key=api_key
)
@CostEstimator()
def query_openai(model, temperature, messages, mock=True, completion_tokens=10):
return client.chat.completions.create(
model=model,
temperature=temperature,
messages=messages,
max_tokens=600)
# We define the run_request method to wrap it with the @backoff decorator
@backoff.on_exception(backoff.expo, (openai.RateLimitError, openai.APIError))
def run_request(system_prompt, user_prompt, model, mock):
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
return query_openai(
model=model,
temperature=0.0,
messages=messages,
mock=mock
)Next, we create a system prompt describing what we want to classify. For further examples of prompts and advice on prompt engineering see e.g. the prompting guide and further resources linked at the bottom of the page.
For the moment we are going to use the prompt from the literature.
Do not forget the Prompt Archive when experimenting. Share your successfull prompt with us!
system_prompt = """
You are an advanced classifying AI. Your task is to classify the sentiment of a text. Sentiment can be either ‘positive’, ‘negative’, or ‘neutral’.
"""prompt = """
Please classify the following social media comment into either ‘negative’, ‘neutral’, or ‘positive’. Your answer MUST be one of [‘negative’, ‘neutral’, ‘positive’], and it should be presented in lowercase.
Text: [TEXT]
"""Running the request.
The following code snippet uses my gpt-cost-estimator package to simulate API requests and calculate a cost estimate. Please run the estimation whne possible to asses the price-tag before sending requests to OpenAI! Make sure run_request and system_prompt (see Setup for GPT) are defined before this block by running the two blocks above!
Fill in the MOCK, RESET_COST, COLUMN, SAMPLE_SIZE, and MODEL variables as needed (see comments above each variable.)
from tqdm.auto import tqdm
#@markdown Do you want to mock the OpenAI request (dry run) to calculate the estimated price?
MOCK = False # @param {type: "boolean"}
#@markdown Do you want to reset the cost estimation when running the query?
RESET_COST = True # @param {type: "boolean"}
#@markdown What's the column name to save the results of the data extraction task to?
COLUMN = 'Sentiment' # @param {type: "string"}
#@markdown Do you want to run the request on a smaller sample of the whole data? (Useful for testing). Enter 0 to run on the whole dataset.
SAMPLE_SIZE = 25 # @param {type: "number", min: 0}
#@markdown Which model do you want to use?
MODEL = "gpt-3.5-turbo-0613" # @param ["gpt-3.5-turbo-0613", "gpt-4-1106-preview", "gpt-4-0613"] {allow-input: true}
# Initializing the empty column
if COLUMN not in df.columns:
df[COLUMN] = None
# Reset Estimates
CostEstimator.reset()
print("Reset Cost Estimation")
filtered_df = df.copy()
# Skip previously annotated rows
filtered_df = filtered_df[pd.isna(filtered_df[COLUMN])]
if SAMPLE_SIZE > 0:
filtered_df = filtered_df.sample(SAMPLE_SIZE)
for index, row in tqdm(filtered_df.iterrows(), total=len(filtered_df)):
try:
p = prompt.replace('[TEXT]', row['Text'])
response = run_request(system_prompt, p, MODEL, MOCK)
if not MOCK:
# Extract the response content
# Adjust the following line according to the structure of the response
r = response.choices[0].message.content
# Update the 'new_df' DataFrame
df.at[index, COLUMN] = r
except Exception as e:
print(f"An error occurred: {e}")
# Optionally, handle the error (e.g., by logging or by setting a default value)
print()Reset Cost EstimationCost: $0.0002 | Total: $0.0069df[~pd.isna(df['Sentiment'])].head()| Unnamed: 0 | shortcode | Text | Text Type | Policy Issues | Sentiment | |
|---|---|---|---|---|---|---|
| 6 | 6 | CyLt56wtNgV | Viele gemischte Gefühle waren das gestern Aben... | Caption | ['Demokratie'] | negative |
| 27 | 27 | CyKwo3Ft6tp | Swipe dich rückwärts durch die Kampagne ✨\n\n🤯... | Caption | ['Soziale Gerechtigkeit'] | positive |
| 29 | 29 | CyKwBKcqi31 | #FREIEWÄHLER jetzt zweite Kraft in Bayern! Gro... | Caption | ['Stärkung der Demokratie', 'Sorgen der Bürger... | positive |
| 66 | 66 | CyIjC3QogWT | In einer gemeinsamen Erklärung der Parteivorsi... | Caption | ['Israel'] | positive |
| 212 | 212 | CyAmHU7qlVc | #FREIEWÄHLER #Aiwanger | Caption | NaN | neutral |
# Save Results
df.to_csv('/content/drive/MyDrive/2023-12-01-Export-Posts-Text-Master.csv')Let’s plot the result for a first big picture
import matplotlib.pyplot as plt
# Count the occurrences of each sentiment
sentiment_counts = df['Sentiment'].value_counts()
# Create a bar chart
sentiment_counts.plot(kind='bar')
# Adding labels and title
plt.xlabel('Sentiment')
plt.ylabel('Count')
plt.title('Sentiment Counts')
# Show the plot
plt.show()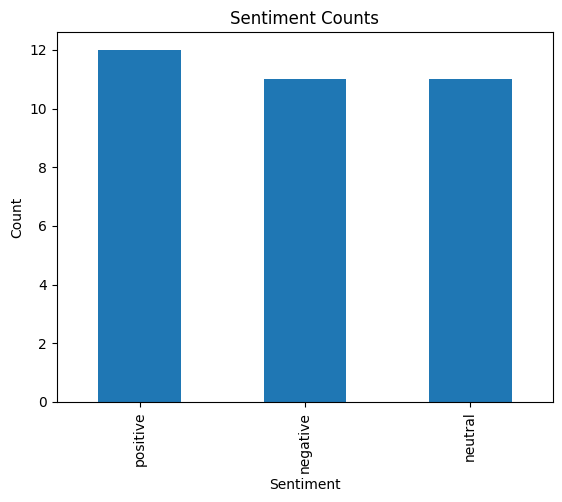
Zero-Shot Multiclass
So far we have been using one request for exactly one classification. Additionally, our classification has been a categorical variable (sentiment). Since GPT natively speaks JSON as well as other file formats, we can easily request our responses to be formated in JSON. As such, we can request the model to return not just one classification at a time, but multiple classifications simultaneously. Above I introduced two theoretically motivated operationalizations. The second example, mobilization, can be measured e.g. as direct vs. indirect calls to action, or online or offline calls. We could model this question as two categorical classification tasks (direct/indirect/NA, online/offline/NA). My example below makes use of so-called dummy variables, where the presence or absence of each value is coded using 1 or 0 (True or False), as a boolean variable. The dummy variables simplifies the prompt and allow cases, where multiple types of calls to action are used in one text.
Prompting for multiclass classification works well when defining the output format to adhere strict formatting rules, for more complex use-cases I recommend using structured outputs with JSON Schemas. The second step is to intpret the GPT response in the right, in our case, to use the json package. Make use of python errors and exceptions to guard your loop against runtime errors. The example below expects all values in the COLUMNS variable to be part of the JSON object returned from the model and saves the result in df’s column of the same name. Python’s dynamic typing usually takes care of casting the model result to boolean, further down the stream we might have to cast the columns manually (i.e. after saving and loading the df from csv.)
Few-Shot Classification
Few-shot learning, involves presenting a model with a small number of task demonstrations at inference time. The number of examples is constrained by the model’s context window capacity. The primary advantage of few-shot learning is the significant reduction in the need for task-specific data, alongside minimizing the risk of learning a narrow distribution from a large, but limited, fine-tuning dataset. However, this method has shown inferior performance compared to state-of-the-art fine-tuned models and still requires a minimal amount of task-specific data (Brown et al. 2020).
system_prompt = """
You are an advanced classifying AI. Your task is to classify the sentiment of a text. Sentiment can be either ‘positive’, ‘negative’, or ‘neutral’.
**Examples:**
"Wir sind EIN Volk! 🇩🇪 In Leipzig nahm es den Anfang, breitete sich aus wie ein Lauffeuer und ebnete den Weg für die deutsche Einheit. Was damals viel Arbeit war, zahlte sich aus. Was heute noch Arbeit ist, wird sich auszahlen. Ein geeintes Deutschland ist keine Selbstverständlichkeit und wir sind dankbar für die Demokratie, den Rechtsstaat und unsere freiheitliche Gesellschaft. Und wir arbeiten täglich dafür, dass uns diese Werte erhalten bleiben.": positive
"FREIE WÄHLER Wir FREIE WÄHLER kämpfen für eine flächendeckende Gesundheitsversorgung auch auf dem Land. HUBERT AJUANGER": neutral
"Die #Grünen sind mit dafür verantwortlich, dass die #Ampel-Regierung in Berlin meilenweit an der Lebenswirklichkeit der Menschen vorbei regiert. Ausgerechnet unter einem grünen Klimaminister lässt die Akzeptanz für #Klimaschutz in der Gesellschaft nach. Mit uns wird es keine Grünen in der Bayerischen Staatsregierung geben.": negative
"""prompt = """
Please classify the following social media comment into either ‘negative’, ‘neutral’, or ‘positive’. Your answer MUST be one of [‘negative’, ‘neutral’, ‘positive’], and it should be presented in lowercase.
Text: [TEXT]
"""Run the Few-Shot request.
The following code snippet uses my gpt-cost-estimator package to simulate API requests and calculate a cost estimate. Please run the estimation whne possible to asses the price-tag before sending requests to OpenAI! Make sure run_request and system_prompt are defined before this block by running the two blocks above (see Setup for GPT)!
Fill in the MOCK, RESET_COST, COLUMN, SAMPLE_SIZE, and MODEL variables as needed (see comments above each variable.)
from tqdm.auto import tqdm
#@markdown Do you want to mock the OpenAI request (dry run) to calculate the estimated price?
MOCK = False # @param {type: "boolean"}
#@markdown Do you want to reset the cost estimation when running the query?
RESET_COST = True # @param {type: "boolean"}
#@markdown What's the column name to save the results of the data extraction task to?
COLUMN = 'Sentiment' # @param {type: "string"}
#@markdown Do you want to run the request on a smaller sample of the whole data? (Useful for testing). Enter 0 to run on the whole dataset.
SAMPLE_SIZE = 25 # @param {type: "number", min: 0}
#@markdown Which model do you want to use?
MODEL = "gpt-3.5-turbo-0613" # @param ["gpt-3.5-turbo-0613", "gpt-4-1106-preview", "gpt-4-0613"] {allow-input: true}
# Initializing the empty column
if COLUMN not in df.columns:
df[COLUMN] = None
# Reset Estimates
CostEstimator.reset()
print("Reset Cost Estimation")
filtered_df = df.copy()
# Skip previously annotated rows
filtered_df = filtered_df[pd.isna(filtered_df[COLUMN])]
if SAMPLE_SIZE > 0:
filtered_df = filtered_df.sample(SAMPLE_SIZE)
for index, row in tqdm(filtered_df.iterrows(), total=len(filtered_df)):
try:
p = prompt.replace('[TEXT]', row['Text'])
response = run_request(system_prompt, p, MODEL, MOCK)
if not MOCK:
# Extract the response content
# Adjust the following line according to the structure of the response
r = response.choices[0].message.content
# Update the 'new_df' DataFrame
df.at[index, COLUMN] = r
except Exception as e:
print(f"An error occurred: {e}")
# Optionally, handle the error (e.g., by logging or by setting a default value)
print()Reset Cost EstimationCost: $0.0010 | Total: $0.0278df[~pd.isna(df['Sentiment'])].sample(5)| Unnamed: 0 | shortcode | Text | Text Type | Policy Issues | Sentiment | |
|---|---|---|---|---|---|---|
| 1833 | 1833 | CxunhdYNvw3 | tanten | OCR | NaN | neutral |
| 2299 | 2299 | CxJAr3Ht7mh | EIN JAHR FEMINISTISCHE REVOLUTION IM IRAN LASS... | OCR | NaN | neutral |
| 369 | 369 | Cx2gzYdIv5d | Wir gratulieren Sven Schulze, der gestern in M... | Caption | NaN | positive |
| 1886 | 1886 | CxqbrYztMdC | Berliner Senat; nachdem er rausgefunden hat, d... | OCR | NaN | negative |
| 290 | 290 | Cx7ruIdiOXb | #TagderdeutschenEinheit \n\nUnser #Bayern hat ... | Caption | ['LosvonBerlin', 'Bayernpartei'] | negative |
# Save Results
df.to_csv('/content/drive/MyDrive/2023-12-01-Export-Posts-Text-Master.csv')import matplotlib.pyplot as plt
# Count the occurrences of each sentiment
sentiment_counts = df['Sentiment'].value_counts()
# Create a bar chart
sentiment_counts.plot(kind='bar')
# Adding labels and title
plt.xlabel('Sentiment')
plt.ylabel('Count')
plt.title('Sentiment Counts')
# Show the plot
plt.show()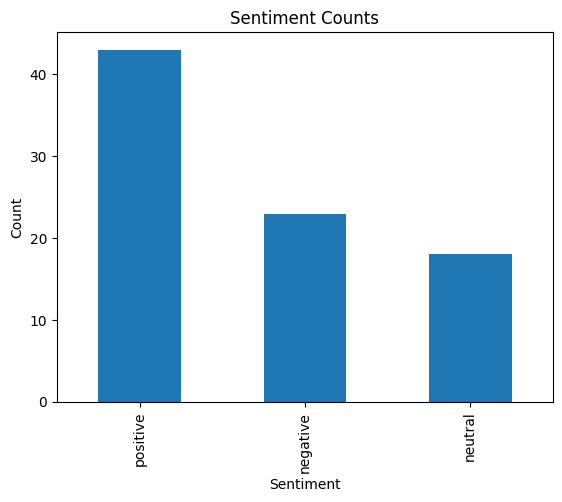
Saving Money – Multidocument Classification
Outdated. Archived Here
Documentation
It is important to document all aspects of the prompt engineering process to ensure reproducibility and validity. See these notes as your lab notes. This includes documenting all prompt versions, the model version, the number of samples used, how test annotations were created, and other critical details that could impact the outcome. Proper documentation also helps in contextualizing the findings and understanding the boundaries within which the results are applicable.
To document effectively, consider taking structured notes, which should include key decisions, changes made during the process, challenges encountered, and how they were addressed. Screenshot are an effective method for documentation. Using consistent formats such as tables or templates can enhance clarity and make it easier to review the work later.
Conclusion
We have scratched the surface of (textual) content analysis as a foundation for our text classification tasks. Starting our journey with the idea of text as data and following the exploration of textual content, we just added a new instrument to our toolbox for computational social media analysis: text classification. We focused solely on prompting and GPT for the classification tasks. There exist several other approaches (e.g. using BERT and other trasnformer models), and several providers offer cloud services and APIs for classification tasks (e.g. in the Google Cloud). For sentiment analysis there are dedicated models (see Schmidt et al. (2022) for the application of such a model), and even more services and APIs (e.g. on Microsoft Azure). I compared the performance of GPT-4o to a fine tuned BERT Model for the binary classification of Calls to Action (Achmann-Denkler et al. 2024). While the dedicated BERT model outperformed GPT-4o, the performance difference was relatively small.
At the same time, the first papers show interesting results when using GPT for text classification (e.g. Brown et al. 2020), with prompt design being accessible for researcher with zero to few experience with machine learning. There is currently a lot of opportunity to experiment with prompts, and to test and evaluate Large Language Models and prompts against fine-tuned and existing models. We are currently missing one last step to setup a complete experiment: The evaluation, which is the next topic of our seminar. While there exists literature about prompting and prompt engineering (see top and further reading), some of the literature has a more technical motivation and is short of practical advice. Through this session I have presented the practical knowledge that I gathered through my last research project (currently under review), which still is experimental. I presented the Zero-Shot and Few-Shot approach, as well as a Zero-Shot Multiclass approach and a Multidocument approach to save money / requests while working with expensive models.
Further Reading
References
Achmann-Denkler, Michael, Jakob Fehle, Mario Haim, and Christian Wolff. 2024. “Detecting Calls to Action in Multimodal Content: Analysis of the 2021 German Federal Election Campaign on Instagram.” In Proceedings of the 4th Workshop on Computational Linguistics for the Political and Social Sciences: Long and Short Papers, edited by Christopher Klamm, Gabriella Lapesa, Simone Paolo Ponzetto, Ines Rehbein, and Indira Sen, 1–13. Vienna, Austria: Association for Computational Linguistics. https://aclanthology.org/2024.cpss-1.1.
Borra, Creators Erik. n.d. “ErikBorra/PromptCompass: Updated models.” https://doi.org/10.5281/zenodo.8359916.
Brown, Tom B, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models are Few-Shot Learners,” May. http://arxiv.org/abs/2005.14165.
Döring, Nicola, and Jürgen Bortz. 2016. Forschungsmethoden und Evaluation in den Sozial- und Humanwissenschaften. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-41089-5.
Gu, Jindong, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Tresp, and Philip Torr. 2023. “A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models,” July. http://arxiv.org/abs/2307.12980.
Haßler, Jörg, Anna Sophie Kümpel, and Jessica Keller. 2021. “Instagram and political campaigning in the 2017 German federal election. A quantitative content analysis of German top politicians’ and parliamentary parties’ posts.” Information, Communication and Society, July, 1–21. https://doi.org/10.1080/1369118X.2021.1954974.
Liu, Bing. 2022. Sentiment Analysis and Opinion Mining. Springer International Publishing. https://doi.org/10.1007/978-3-031-02145-9.
Liu, Pengfei, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. “Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.” ACM Comput. Surv. 55 (9): 1–35. https://doi.org/10.1145/3560815.
Møller, Anders Giovanni, Jacob Aarup Dalsgaard, Arianna Pera, and Luca Maria Aiello. 2023. “Is a prompt and a few samples all you need? Using GPT-4 for data augmentation in low-resource classification tasks,” April. http://arxiv.org/abs/2304.13861.
Nguyen, Dong, Maria Liakata, Simon DeDeo, Jacob Eisenstein, David Mimno, Rebekah Tromble, and Jane Winters. 2020. “How We Do Things With Words: Analyzing Text as Social and Cultural Data.” Frontiers in Artificial Intelligence 3 (August): 62. https://doi.org/10.3389/frai.2020.00062.
Schmidt, Thomas, Jakob Fehle, Maximilian Weissenbacher, Jonathan Richter, Philipp Gottschalk, and Christian Wolff. 2022. “Sentiment Analysis on Twitter for the Major German Parties during the 2021 German Federal Election.” In Proceedings of the 18th Conference on Natural Language Processing (KONVENS 2022), 74–87. Potsdam, Germany: KONVENS 2022 Organizers. https://aclanthology.org/2022.konvens-1.9.
Törnberg, Petter. 2024. “Best Practices for Text Annotation with Large Language Models.” arXiv [Cs.CL], February. http://arxiv.org/abs/2402.05129.
White, Jules, Quchen Fu, Sam Hays, Michael Sandborn, Carlos Olea, Henry Gilbert, Ashraf Elnashar, Jesse Spencer-Smith, and Douglas C Schmidt. 2023. “A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT,” February. http://arxiv.org/abs/2302.11382.
Wurst, Anna-Katharina, Katharina Pohl, and Jörg Haßler. 2023. “Mobilization in the Context of Campaign Functions and Citizen Participation.” Media and Communication 11 (3). https://doi.org/10.17645/mac.v11i3.6660.
Zamfirescu-Pereira, J D, Richmond Y Wong, Bjoern Hartmann, and Qian Yang. 2023. “Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts.” In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 1–21. CHI ’23, Article 437. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3544548.3581388.
Zhao, Zihao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. “Calibrate Before Use: Improving Few-shot Performance of Language Models.” In Proceedings of the 38th International Conference on Machine Learning, edited by Marina Meila and Tong Zhang, 139:12697–706. Proceedings of Machine Learning Research. PMLR. https://proceedings.mlr.press/v139/zhao21c.html.
Ziems, Caleb, William Held, Omar Shaikh, Jiaao Chen, Zhehao Zhang, and Diyi Yang. 2024. “Can Large language models transform computational social science?” Computational Linguistics (Association for Computational Linguistics) 50 (1): 1–55. https://doi.org/10.1162/coli\_a\_00502.
Reuse
Citation
BibTeX citation:
@online{achmann-denkler2024,
author = {Achmann-Denkler, Michael},
title = {Text {Classification}},
date = {2024-11-25},
url = {https://social-media-lab.net/processing/classification.html},
doi = {10.5281/zenodo.10039756},
langid = {en}
}
For attribution, please cite this work as:
Achmann-Denkler, Michael. 2024. “Text Classification.”
November 25, 2024. https://doi.org/10.5281/zenodo.10039756.