Instagram Stories

Instagram stories, characterized by their ephemeral nature, expire after 24 hours. Therefore, it’s crucial to collect them in a timely manner, as retrospective data collection is not an option with this format. There are two feasible methods: The Tidal Tales Plugin and Instaloader. Additionally, commercial tools such as 4k Stogram1 PhantomBuster are also available.
Overall, the ephemeral nature of stories necessitates our continuous monitoring and data collection from our targeted profiles. To ensure that we capture every story item, I recommend collecting stories twice daily, approximately 12 hours apart. This method accounts for potential inaccuracies in timing, as the intervals overlap. Data can be gathered manually or through computational means. The manual approach, especially in conjunction with the Tidal Tales Plugin, is preferable as we do not circumvent any technical measures to collect our data. For this method, we would install the plugin and view all stories in our browser twice daily. Alternatively, using Instaloader involves simply initiating the command and waiting for the software to gather all the data. Optimally, we could utilize tools like Cron to automate this process.
Tidal Tales Plugin
![]()
This method is based on the Zeeschuimer Firefox Plugin. I have adapted the original plugin to create the Tidal Tales Plugin (Achmann-Denkler and Wolff 2024), which is specifically tailored for collecting Instagram stories for real-time data collection. The plugin is available on GitHub. To use it, download the latest version via Firefox and install the plugin. Follow these steps to download stories using the Tidal Tales Plugin:
- Download and install the plugin.
- Regularly view stories in Firefox to collect them.
- Save the CSV file for the collected data.
Plugin Installation
To install the plugin:
- Use Firefox to visit the latest release page on GitHub.
- Download the
.xpifile, and Firefox will ask permission to install the extension. - Allow the installation, and you are good to go!
The plugin adds a button to the browser’s menu bar. Click on the Tidal Tales logo to check the progress of the current collection.
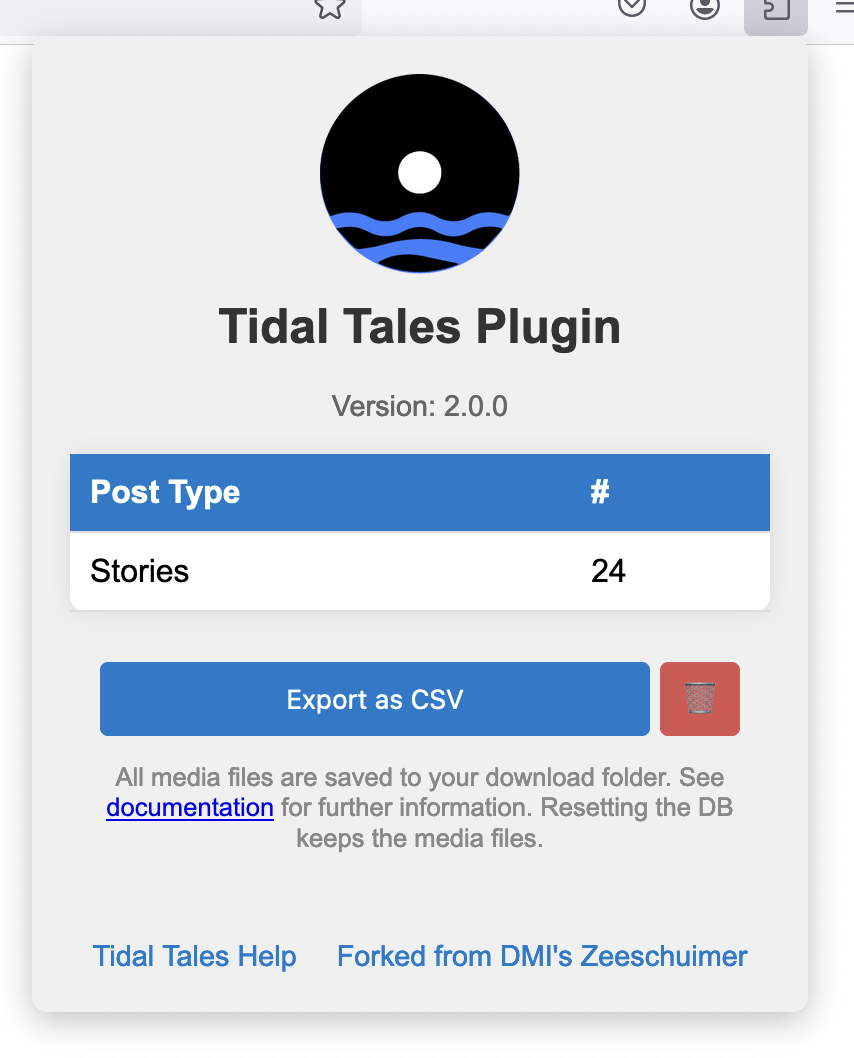
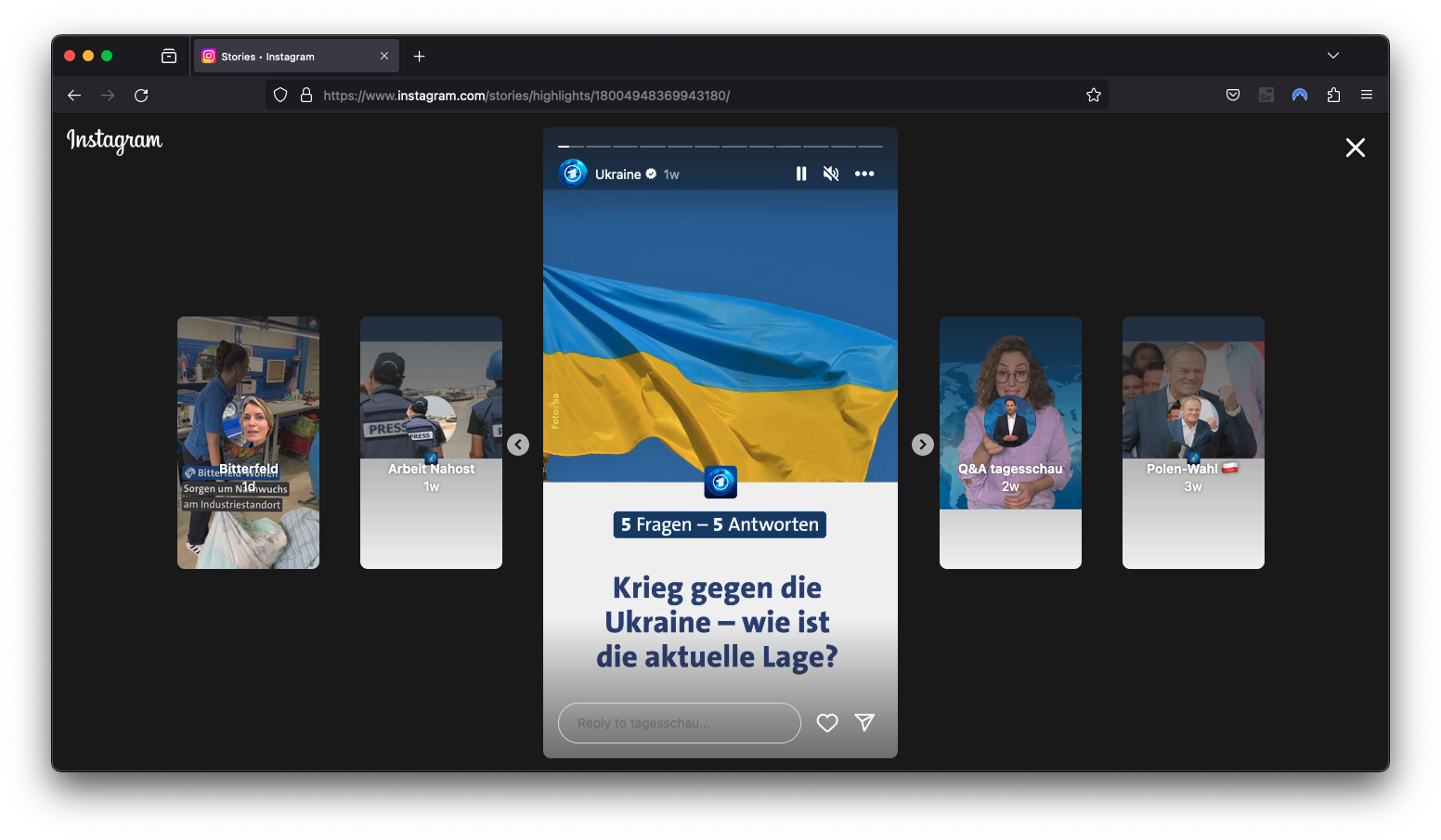
Visit Instagram as usual. Open the first stories, and the plugin captures all data in the background. The media files (images, videos) are stored in your downloads folder, along with all metadata (JSON files). At the same time, the metadata is stored in a database inside your local Firefox browser. Once the collection is done, open the Tidal Tales interface and click the “Export as CSV” button. The plugin converts the metadata of each collected story into a table with columns like Username, image_path or Time of Posting. This table can easily be integrated into the following chapters’ computational analyses.
Pros:
- We do not circumvent any technical measures: We view the stories as a normal user und archive the data exchanged between our browser and the server.
- Collects all data: metadata, images, videos
- Collection takes place on the local machine. No servers / external services needed.
Cons:
- We need to manually browse the stories twice a day (can be automated using Selenium)
Instaloader
Instaloader for Stories operates in a manner akin to collecting Posts. Initially, the package must be installed:
!pip -q install instaloaderUnlike the method outlined in the previous tutorial, I advise employing the command-line interface of Instaloader for collecting stories. To do this, open a terminal and execute the command below:
instaloader --login your.profile.name --dirname-pattern ig_stories/{profile} :stories --no-compress-jsonExecuting this command generates a dedicated subfolder within ig_stories for each user followed by your profile. It downloads the metadata, images, and videos of each story. The metadata is saved in a JSON file. While these files are typically xz-compressed by default, using the --no-compress-json option prevents this compression. Subsequently, the JSON files can be imported into a pandas DataFrame in Python.
This process can be automated, for example, by utilizing a bash script in conjunction with cron:
#!/bin/bash
# Generate a random number of seconds between 0 and 3600 (1 hours)
sleep_duration=$(( RANDOM % 3600 ))
# Print the sleep duration
echo "Sleeping for $sleep_duration seconds..."
# Sleep for the random duration
sleep $sleep_duration
# Run Instaloader command to download the latest Instagram stories
instaloader --login your.profile.name --dirname-pattern ~/ig_stories/{profile} :stories --no-compress-json
# Add more script to check for success and send alerts in case of errorStart cron by entering crontab -e on your terminal and add a line pointing to the bash script, e.g.:
* 8,20 * * * /path/to/your/script.sh >/dev/null 2>&1Pros:
- Very easy to automate
- Collects all data: metadata, images, videos
Cons:
- Possibly against the TOS
- Rate Limits
- Blocked Accounts (very quickly)
Conclusion
This page offers an overview of two methods for collecting ephemeral Instagram stories, which are crucial to capture in real time due to their 24-hour expiration period. The first method, instaloader, is theoretically effective. However, similar to the case with posts, Instagram accounts utilizing Instaloader face a high risk of being banned swiftly.
The second approach adopts a less invasive strategy. It involves capturing the data transmitted to the browser while viewing stories on Instagram, and then transferring the metadata to our Firebase project. Upon the addition of a new story to the database, the backend initiates the download of videos and images for that story.
To facilitate this process, I have provided a notebook for project creation, a manual for configuring the plugin, and additional code to export the captured stories via a Jupyter notebook.
References
Footnotes
Discontinued.↩︎
Reuse
Citation
@online{achmann-denkler2024,
author = {Achmann-Denkler, Michael},
title = {Instagram {Stories}},
date = {2024-11-14},
url = {https://social-media-lab.net/data-collection/ig-stories.html},
doi = {10.5281/zenodo.10039756},
langid = {en}
}