
!pip -q install instaloader |████████████████████████████████| 60 kB 3.0 MB/s eta 0:00:011
Building wheel for instaloader (setup.py) ... doneInstagram offers two ways of image sharing: permanent posts and ephemeral stories. In this chapter I will offer three approaches for collecting posts: Instaloader, CrowdTangle, and Zeeschuimer.
Posts are shaped by several affordances and contain different type of media: least one image or video, often paired with text (captions). Posts may also contain an album consisting of more than one image or video. Captions may contain hashtags and / or mentions. Hashtags are used to self-organize posts on the platform, users can subscribe to hashtags and search for them. Mentions are used to link a post to another profile. Moreover, users can like, share and comment posts. Some data-collection approaches, like CrowdTangle, offer access to one image and post metrics, like the comment and like count. Instaloader, offer access to all images / videos, while being the legally most questionable approach. And then there’s the middle ground: Zeeschuimer (optionally in connection with 4CAT).
Through the following subchapters I will try to illuminate the advantages of each collection methods. For each method I will provide a manual to follow in order to collect metadata and the actual media for Instagram posts.
As of November 2024 I recommend to collect posts using Zeeschuimer or the official Meta Content Library. Our preferred approach for the 2024/25 winter semester is the combination Zeeschuimer + Import Notebook where we import the ndjson created by Zeeschuimer into a custom notebook and convert the data and download images and videos. An updated notebook for downloading album posts will be added shortly.
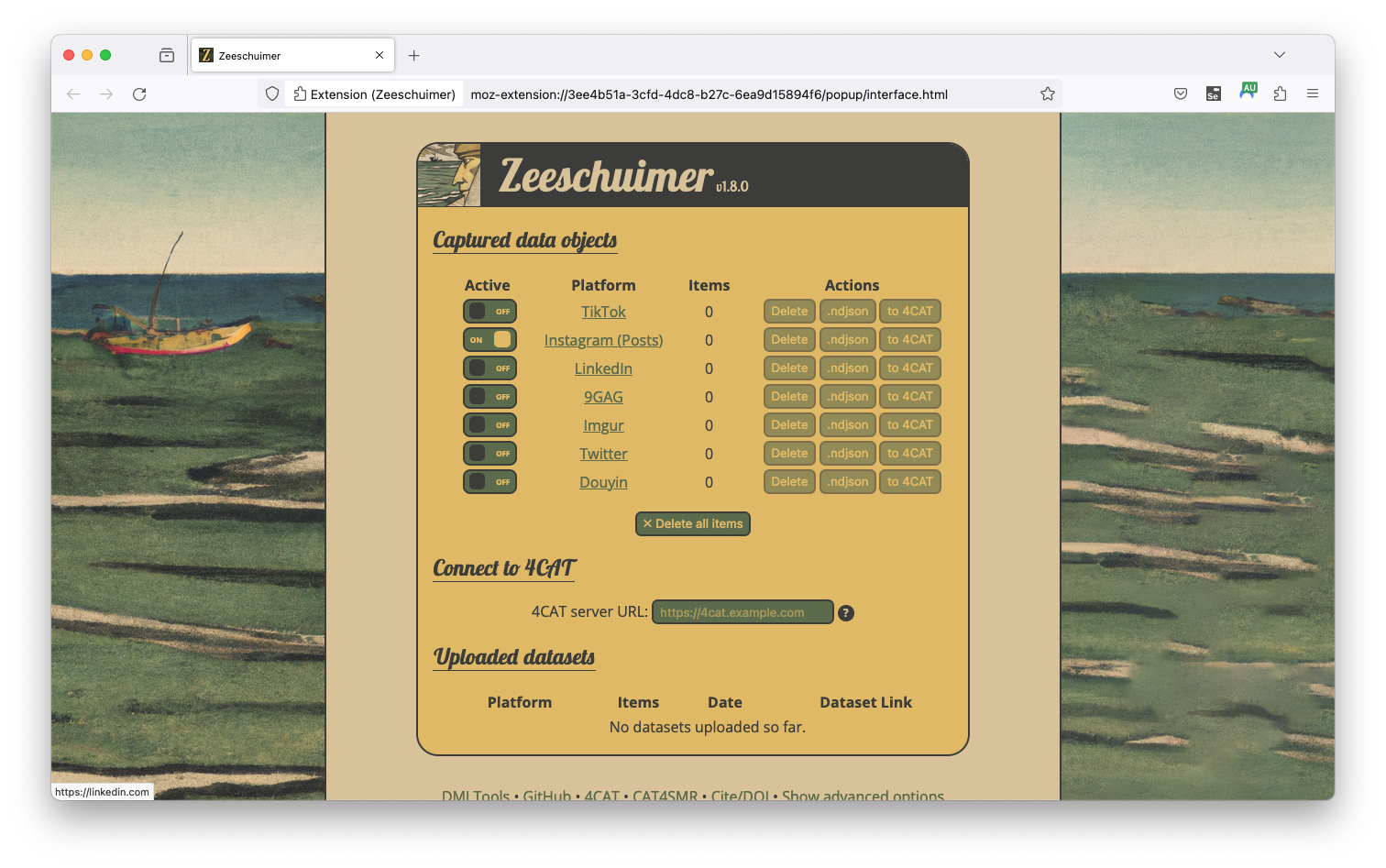
Zeeschuimer (Peeters, n.d.) and 4CAT (Peeters, Hagen, and Wahl, n.d.) are two tools developed for the https://wiki.digitalmethods.net/. The first is a firefox plugin that captures traffic when browsing websites likes Instagram or TikTok. The second, 4CAT, is an analysis platform incorporating several steps of preprocessing and further analyses. For post collection we can use the original Zeeschuimer Firefox Plugin, download the latest release from GitHub and install it in Firefox. To download Instagram posts using Zeeschuimer follow these steps (* steps are only necessary when working with 4CAT):
https://4cat.digitalhumanities.io/).Data collected using Zeeschuimer can also be exported as ndjson files. The Zeeschuimer Import Notebook provides a code example for reading the files and converting them to either 4CAT format, or a table format compatible with the above notebooks for CrowdTangle and instaloader.
The old version of the Notebook still exists. This version downloads only one image per post.
This is our preferred approach for the research seminar. We take a closer look at the Data Structure and Preprocessing of Zeeschuimer data through custom notebooks over the course of the next weeks.
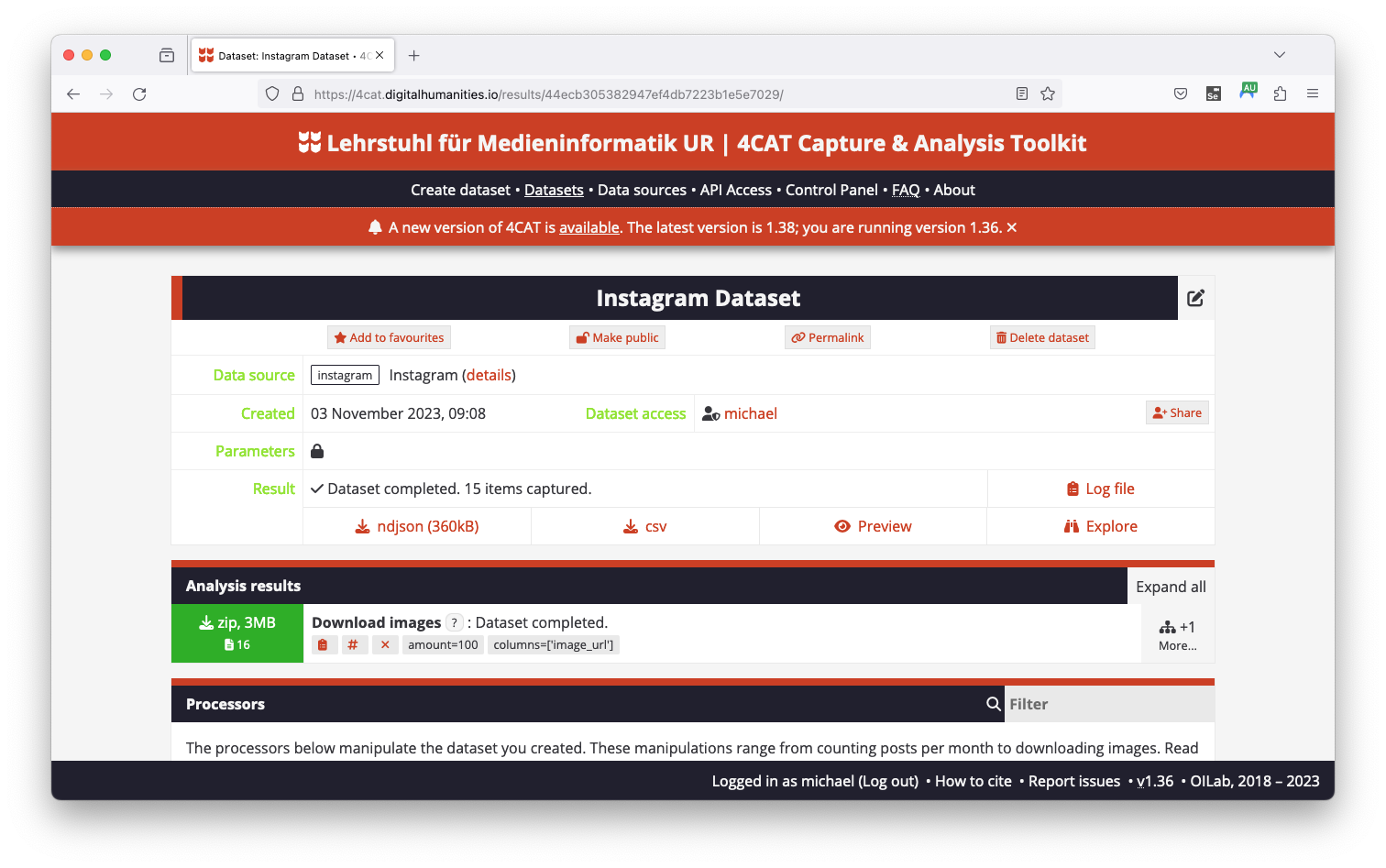
4CAT is a tool developed by the Digital Methods Initiative. The collected data can be exported to 4CAT with only the click of a button. After successfully importing the post data, the tools offers several modules. At first, download the images associated with each post with the Download images module at the bottom. Select image_url in the options tab and hit Run.

Once the images have been downloaded more analysis options are available when clicking the More button on the right. Further, you may download images as a ZIP file and can export the posts from 4CAT in CSV format. Repeat the process with the Download Video function to access posted videos. We will be able to use the collected data using the CSV export and the media files provided in the ZIP packages. Additionally, each ZIP file contains a .metadata.json file which we may use to map filenames to media files.
The authors of Zeeschuimer and 4CAT have published a manual here.
Instaloader is a python package for downloading instagram pictures and videos along with their metadata. I have written a getting started tutorial on Medium. It is, together with the provided notebook, the basis for this chapter.
Instaloader is a stand-alone piece of software: It offers options to download most Instagram content, like posts and stories, through different strategies, e.g. lists of profiles or by hashtag. For complex tasks I recommend to call instaloader from terminal, see the documentation for more information.
Meta shut down CrowdTangle in August 2024. The tool has been replaced by the Meta Content Library. Researchers can apply for access, a third party now moderates access, the Inter-university Consortium for Political and Social Research (ICPSR). I will update this page shortly.
CrowdTangle is the best option to collect IG posts – in theory. It provides legal access to Instagram data and offers several tools to export large amount of data. For a current project we’ve exported more than 500.000 public posts through a hashtag query. Unfortunately there are several restrictions: CrowdTangle is the best tool to export metadata of public posts, and captions. The abilty to collect images through the platform is limited: Image links expire after a certain amount of time, thus we need to use some makeshift approach to download the images. When we can download the images, it’s always just one per post, no matter if it’s a gallery or a single image. And let’s not talk about videos. I have written another Medium story with a step-by-step guide to CrowdTangle.
@online{achmann-denkler2024,
author = {Achmann-Denkler, Michael},
title = {Instagram {Posts}},
date = {2024-11-14},
url = {https://social-media-lab.net/data-collection/ig-posts.html},
doi = {10.5281/zenodo.10039756},
langid = {en}
}