
!pip install -q google-cloud-aiplatform backoffEnsemble Image Classification
In this chapter, we explore an approach known as ensemble classification, which I have just been experimenting with. At this stage, the methodology is in an early phase, with comprehensive evaluations and literature comparisons yet to be conducted.
The core concept of our ensemble method is to synthesize a rich set of inputs for the GPT model, specifically tailored to enhance its ability to classify images without direct visual analysis. In the example below we achieve this by integrating Captions, Objects, and OCR (Optical Character Recognition) data, each element extracted and processed by distinct, specialized models. This preparatory processing transforms the raw image into a multi-faceted textual representation, compatible with LLMs. The power of our ensemble approach comes from combining different types of data. By doing so, we leverage the specific strengths of each model used in the process.
The idea behind our ensemble approach here is to provide the GPT model with Captions, Objects, and OCR detected and generated by different models. The final classification using the GPT prompt below relies solely on the outputs of the previous models. In other words: The final classification takes places without the actual image. This approach complements image classification approaches based on GPT and CLIP introduced in the image classification chapter.
The process is illustrated in the following schematic, detailing the sequential flow from image to classification:
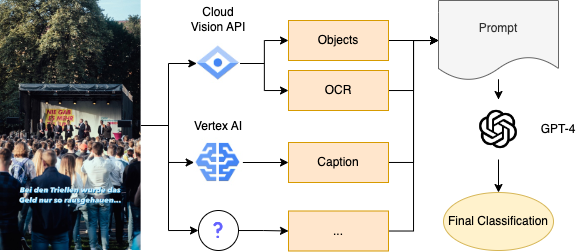
In practice, this approach has shown promising consistency, particularly when compared to methods relying solely on CLIP for image classification, as discussed in the image classification chapter. Nevertheless, as the example below illustrates, the technique is not perfect. My first trials with GPT-3.5 yielded suboptimal results, thus I recommend employing GPT-4 for its advanced capabilities.
An advantage – especially in contrast to multimodal LLMs – of this ensemble method is the control it gives over the input variables. Depending on the specific requirements of your analysis, you can fine-tune the focus of the ensemble. For instance, if textual content is important, emphasizing OCR might be beneficial. Conversely, if the context provided by objects within the image is more relevant, then prioritizing object detection would be advantageous. This flexibility allows for tailored, context-sensitive classifications.
To explore the application of this technique, the following notebook will guide you through the steps necessary to extract Captions, Objects, and OCR using Google Vision APIs. This hands-on approach aims not just to illustrate the theory but also to equip you with practical skills in implementing this innovative classification strategy.
Notebook
This notebook guides you through several steps to obtain information on each image using the Google Vision, and Google Vertex API. Additionally, I added a section to use an open source approach to image captioning. In my opinion vertex produces the better captions.
Captions using Google Vertex AI
Several providers, like Microsoft and Google provide cloud services for the generation of image captions. Additionally, we can use multimodal GPT-4 for image captioning.
Get started by first installing the necessary packages.
Next, we initialize a GoogleAPI class, which is initialized using a cloud credential file. I described how to obtain a credential file in this medium article. In contrast to the linked manual, we need to add the Vertex AI Administrator role to the service account. Download the JSON file to your device and place the file in the directory of this notebook / upload it to Colab for captioning images.
Additionally: Activate the Vertex AI API in the Google Cloud Console.
import requests
import base64
import subprocess
import numpy as np
import time
import backoff
from google.oauth2 import service_account
import google.auth.transport.requests
class GoogleAPI:
def __init__(self, project_id, credentials_json):
self.credentials = self.get_google_credentials(credentials_json)
self.token = self.get_gcloud_access_token()
self.project_id = project_id
def get_google_credentials(self, credentials_json):
credentials = service_account.Credentials.from_service_account_file(
credentials_json, scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
return credentials
def get_gcloud_access_token(self):
request = google.auth.transport.requests.Request()
self.credentials.refresh(request)
return self.credentials.token
@backoff.on_exception(backoff.constant, requests.exceptions.RequestException, interval=0.2, max_tries=5)
def make_request(self, image_url, link_type="URL", response_count=1, language_code="en"):
if link_type == "URL":
image_content = self.get_image_from_signed_url(image_url)
b64_image = self.image_to_base64(image_content)
else:
b64_image = self.base64_from_file(image_url)
json_data = {
"instances": [
{
"image": {
"bytesBase64Encoded": b64_image
}
}
],
"parameters": {
"sampleCount": response_count,
"language": language_code
}
}
url = f"https://us-central1-aiplatform.googleapis.com/v1/projects/{self.project_id}/locations/us-central1/publishers/google/models/imagetext:predict"
headers = {
"Authorization": f"Bearer {self.token}",
"Content-Type": "application/json; charset=utf-8"
}
try:
response = requests.post(url, headers=headers, json=json_data)
time.sleep(0.2) # Ensure not to exceed 5 requests per second
if response.status_code == 401:
# Refresh the token and retry
self.token = self.get_gcloud_access_token()
headers["Authorization"] = f"Bearer {self.token}"
response = requests.post(url, headers=headers, json=json_data)
response.raise_for_status() # Raise an exception for HTTP errors
response_data = response.json()
# Check for predictions and return them
predictions = response_data.get('predictions', [])
if predictions:
return predictions[0] # Return the first prediction
else:
return None # or return an empty string "", based on your preference
except requests.HTTPError as e:
print(f"Error for URL {image_url}: {e}")
return np.nan
@staticmethod
def get_image_from_signed_url(url):
response = requests.get(url)
response.raise_for_status()
return response.content
@staticmethod
def base64_from_file(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
@staticmethod
def image_to_base64(image_content):
return base64.b64encode(image_content).decode('utf-8')Now we’re ready to initialize the our api instance. Provide your project_id and the path to your credentials file.
Next, we will run a loop and create one caption per image.
Note: My implementation slows the process down to handle requests/minute limits by google cloud. Our Course project has a limit set to 300 requests / minute.
from tqdm.notebook import tqdm
captions = []
sample = df.copy()
if not 'Vertex Caption' in sample:
sample['Vertex Caption'] = None
for index, row in tqdm(sample.iterrows(), total=len(sample)):
if pd.isna(row['Vertex Caption']):
try:
caption = api.make_request(row['image_path'], link_type="file")
captions.append({
'image_path': row['image_path'],
'Vertex Caption': caption
})
except:
print(f"Error with image {row['image_path']}")
else:
continueError with image /content/media/images/afd.bund/2632909594311219564_1484534097.jpg
Error with image /content/media/images/afd.bund/2637169242765597715_1484534097.jpg
Error with image /content/media/images/afd.bund/2637310044636651340_1484534097.jpg
Error with image /content/media/images/afd.bund/2640856259194124126_1484534097.jpg
Error with image /content/media/images/afd.bund/2643802824089930195_1484534097.jpg
Error with image /content/media/images/afd.bund/2653863205891438589_1484534097.jpg
Error with image /content/media/images/afd.bund/2664113842957989541_1484534097.jpg
Error with image /content/media/images/afd.bund/2671444844831156334_1484534097.jpgThroughout the notebook we will add piece by piece the newly obtained information to the initial dataframe, expanding it one column at a time.
| image_path | Vertex Caption | |
|---|---|---|
| 0 | /content/media/images/afd.bund/212537388606051... | an ad for facebook shows a drawing of a facebo... |
| 1 | /content/media/images/afd.bund/212537470102207... | an advertisement for youtube with a red backgr... |
| 2 | /content/media/images/afd.bund/249085122621717... | an advertisement for telegram with a blue back... |
| 3 | /content/media/images/afd.bund/260084001188499... | two women are sitting at a table talking to ea... |
| 4 | /content/media/images/afd.bund/260085279483160... | a camera is recording a man sitting at a table... |
| Unnamed: 0.2 | Unnamed: 0.1 | Unnamed: 0 | ID | Time of Posting | Type of Content | video_url | image_url | Username | Video Length (s) | ... | Caption | Is Verified | Stickers | Accessibility Caption | Attribution URL | image_path | OCR | Objects | caption | Vertex Caption | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 2125373886060513565_1484534097 | 2019-09-04 08:05:27 | Image | NaN | NaN | afd.bund | NaN | ... | NaN | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537388606051... | FACEBOOK\nAfD\nf\nSwipe up\nund werde Fan! | NaN | a collage of a picture of a person flying a kite | an ad for facebook shows a drawing of a facebo... |
| 1 | 1 | 1 | 2 | 2125374701022077222_1484534097 | 2019-09-04 08:07:04 | Image | NaN | NaN | afd.bund | NaN | ... | NaN | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537470102207... | YOUTUBE\nAfD\nSwipe up\nund abonniere uns! | NaN | a poster of a man with a red face | an advertisement for youtube with a red backgr... |
| 2 | 2 | 2 | 3 | 2490851226217175299_1484534097 | 2021-01-20 14:23:30 | Image | NaN | NaN | afd.bund | NaN | ... | NaN | True | [] | Photo by Alternative für Deutschland on Januar... | NaN | /content/media/images/afd.bund/249085122621717... | TELEGRAM\nAfD\nSwipe up\nund folge uns! | NaN | a large blue and white photo of a plane | an advertisement for telegram with a blue back... |
| 3 | 3 | 3 | 4 | 2600840011884997131_1484534097 | 2021-06-21 08:31:45 | Image | NaN | NaN | afd.bund | NaN | ... | NaN | True | [] | Photo by Alternative für Deutschland on June 2... | NaN | /content/media/images/afd.bund/260084001188499... | Pol\nBeih | 3x Person, 1x Chair, 1x Table, 1x Picture frame | a woman sitting at a desk with a laptop | two women are sitting at a table talking to ea... |
| 4 | 4 | 4 | 5 | 2600852794831609459_1484534097 | 2021-06-21 08:57:09 | Image | NaN | NaN | afd.bund | NaN | ... | NaN | True | [] | Photo by Alternative für Deutschland in Berlin... | NaN | /content/media/images/afd.bund/260085279483160... | BERLIN, GERMANY\n2160 25.000\nMON 422 150M\nA0... | 4x Person, 1x Furniture, 1x Television | a man sitting in front of a screen with a tv | a camera is recording a man sitting at a table... |
5 rows × 21 columns
Let’s save the progress with every step.
Open Source Model
This is an open source approach to image captioning. It runs well on Colab CPUs.
from tqdm.notebook import tqdm
captions = []
for index, row in tqdm(df.iterrows(), total=len(df)):
try:
if True:
caption = image_to_text(row['image_path'], max_new_tokens=30)
if len(caption) == 1:
caption = caption[0].get('generated_text', "")
else:
caption = ""
captions.append({
'image_path': row['image_path'],
'caption': caption
})
except:
continue| image_path | caption | |
|---|---|---|
| 0 | /content/media/images/afd.bund/212537388606051... | a collage of a picture of a person flying a kite |
| 1 | /content/media/images/afd.bund/212537470102207... | a poster of a man with a red face |
| 2 | /content/media/images/afd.bund/249085122621717... | a large blue and white photo of a plane |
| 3 | /content/media/images/afd.bund/260084001188499... | a woman sitting at a desk with a laptop |
| 4 | /content/media/images/afd.bund/260085279483160... | a man sitting in front of a screen with a tv |
| Unnamed: 0.1 | Unnamed: 0 | ID | Time of Posting | Type of Content | video_url | image_url | Username | Video Length (s) | Expiration | Caption | Is Verified | Stickers | Accessibility Caption | Attribution URL | image_path | image | OCR | Objects | caption | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2125373886060513565_1484534097 | 2019-09-04 08:05:27 | Image | NaN | NaN | afd.bund | NaN | 2019-09-05 08:05:27 | NaN | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537388606051... | /content/media/images/afd.bund/212537388606051... | FACEBOOK\nAfD\nf\nSwipe up\nund werde Fan! | NaN | a collage of a picture of a person flying a kite |
| 1 | 1 | 2 | 2125374701022077222_1484534097 | 2019-09-04 08:07:04 | Image | NaN | NaN | afd.bund | NaN | 2019-09-05 08:07:04 | NaN | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537470102207... | /content/media/images/afd.bund/212537470102207... | YOUTUBE\nAfD\nSwipe up\nund abonniere uns! | NaN | a poster of a man with a red face |
| 2 | 2 | 3 | 2490851226217175299_1484534097 | 2021-01-20 14:23:30 | Image | NaN | NaN | afd.bund | NaN | 2021-01-21 14:23:30 | NaN | True | [] | Photo by Alternative für Deutschland on Januar... | NaN | /content/media/images/afd.bund/249085122621717... | /content/media/images/afd.bund/249085122621717... | TELEGRAM\nAfD\nSwipe up\nund folge uns! | NaN | a large blue and white photo of a plane |
| 3 | 3 | 4 | 2600840011884997131_1484534097 | 2021-06-21 08:31:45 | Image | NaN | NaN | afd.bund | NaN | 2021-06-22 08:31:45 | NaN | True | [] | Photo by Alternative für Deutschland on June 2... | NaN | /content/media/images/afd.bund/260084001188499... | /content/media/images/afd.bund/260084001188499... | Pol\nBeih | 3x Person, 1x Chair, 1x Table, 1x Picture frame | a woman sitting at a desk with a laptop |
| 4 | 4 | 5 | 2600852794831609459_1484534097 | 2021-06-21 08:57:09 | Image | NaN | NaN | afd.bund | NaN | 2021-06-22 08:57:09 | NaN | True | [] | Photo by Alternative für Deutschland in Berlin... | NaN | /content/media/images/afd.bund/260085279483160... | /content/media/images/afd.bund/260085279483160... | BERLIN, GERMANY\n2160 25.000\nMON 422 150M\nA0... | 4x Person, 1x Furniture, 1x Television | a man sitting in front of a screen with a tv |
Google Vision Object Detection
Next, we want to detect objects and conduct OCR using the Google Vision API. Install the package and provide the information on your project_id and credential file. (Yes, you have to do this again!).
Important Activate the API in your cloud console and add the VisionAI Admin role to your service account before proceeding!
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/442.1 kB ? eta -:--:-- ━━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 41.0/442.1 kB 1.1 MB/s eta 0:00:01 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━ 378.9/442.1 kB 5.1 MB/s eta 0:00:01 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 442.1/442.1 kB 4.8 MB/s eta 0:00:00
env: GOOGLE_CLOUD_PROJECT=vsma-course-2324
env: GOOGLE_APPLICATION_CREDENTIALS=/content/vsma-course-2324-72da2075ad3a.jsonLet’s define a method to open an image, send it to the vision API, and return all objects (taken from the documentation).
from google.cloud import vision
def localize_objects(path):
"""Localize objects in the local image.
Args:
path: The path to the local file.
"""
with open(path, "rb") as image_file:
content = image_file.read()
image = vision.Image(content=content)
return client.object_localization(image=image).localized_object_annotations… and apply it in a loop across all images …
from tqdm.notebook import tqdm
results = []
for _, row in tqdm(df.iterrows(), total=df.shape[0]):
image_path = row['image_path']
try:
objects = localize_objects(image_path)
for object_ in objects:
vertices = [{"x": vertex.x, "y": vertex.y} for vertex in object_.bounding_poly.normalized_vertices]
result = {
"image_path": row['image_path'],
"object_name": object_.name,
"confidence": object_.score,
"vertices": vertices
}
results.append(result)
except:
print("Exception, e.g. file not found")
objects_df = pd.DataFrame(results)Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found| image | object_name | confidence | vertices | |
|---|---|---|---|---|
| 0 | /content/media/images/afd.bund/260084001188499... | Person | 0.887043 | [{'x': 0.4368581771850586, 'y': 0.398875594139... |
| 1 | /content/media/images/afd.bund/260084001188499... | Person | 0.811766 | [{'x': 0.1969735026359558, 'y': 0.411388963460... |
| 2 | /content/media/images/afd.bund/260084001188499... | Chair | 0.791680 | [{'x': 0.16379289329051971, 'y': 0.50521653890... |
| 3 | /content/media/images/afd.bund/260084001188499... | Table | 0.760902 | [{'x': 0.3676823079586029, 'y': 0.516319274902... |
| 4 | /content/media/images/afd.bund/260084001188499... | Person | 0.709249 | [{'x': 0.20669478178024292, 'y': 0.39929386973... |
This time we save the objects table seperately as we have one row per detected object, rather than one row per image.
Next, let’s do OCR using Google Vision. Once more we define the method to open an image, send it to the API and return the OCR results. (Once more from the documentation)
… and let’s loop it …
from tqdm.notebook import tqdm
results = []
for _, row in tqdm(df.iterrows(), total=df.shape[0]):
image_path = row['image_path']
try:
texts = detect_text(image_path)
text = ""
if len(texts) > 0:
text = texts[0].description
result = {
"image_path": row['image_path'],
"OCR": text
}
results.append(result)
except:
print("Exception, e.g. file not found")
text_df = pd.DataFrame(results)Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not found
Exception, e.g. file not foundThis time we merge the OCR results with our dataframe and save the extended file to our drive.
| Unnamed: 0 | ID | Time of Posting | Type of Content | video_url | image_url | Username | Video Length (s) | Expiration | Caption | Is Verified | Stickers | Accessibility Caption | Attribution URL | image_path | image | OCR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2125373886060513565_1484534097 | 2019-09-04 08:05:27 | Image | NaN | NaN | afd.bund | NaN | 2019-09-05 08:05:27 | NaN | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537388606051... | /content/media/images/afd.bund/212537388606051... | FACEBOOK\nAfD\nf\nSwipe up\nund werde Fan! |
| 1 | 2 | 2125374701022077222_1484534097 | 2019-09-04 08:07:04 | Image | NaN | NaN | afd.bund | NaN | 2019-09-05 08:07:04 | NaN | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537470102207... | /content/media/images/afd.bund/212537470102207... | YOUTUBE\nAfD\nSwipe up\nund abonniere uns! |
| 2 | 3 | 2490851226217175299_1484534097 | 2021-01-20 14:23:30 | Image | NaN | NaN | afd.bund | NaN | 2021-01-21 14:23:30 | NaN | True | [] | Photo by Alternative für Deutschland on Januar... | NaN | /content/media/images/afd.bund/249085122621717... | /content/media/images/afd.bund/249085122621717... | TELEGRAM\nAfD\nSwipe up\nund folge uns! |
| 3 | 4 | 2600840011884997131_1484534097 | 2021-06-21 08:31:45 | Image | NaN | NaN | afd.bund | NaN | 2021-06-22 08:31:45 | NaN | True | [] | Photo by Alternative für Deutschland on June 2... | NaN | /content/media/images/afd.bund/260084001188499... | /content/media/images/afd.bund/260084001188499... | Pol\nBeih |
| 4 | 5 | 2600852794831609459_1484534097 | 2021-06-21 08:57:09 | Image | NaN | NaN | afd.bund | NaN | 2021-06-22 08:57:09 | NaN | True | [] | Photo by Alternative für Deutschland in Berlin... | NaN | /content/media/images/afd.bund/260085279483160... | /content/media/images/afd.bund/260085279483160... | BERLIN, GERMANY\n2160 25.000\nMON 422 150M\nA0... |
Now we do something strange: Let’s count objects and create one string per image, with the structure 1x Person, 1x Chair, …. We are going to add this string to the column Objects of our dataframe.
object_texts = []
for index, row in tqdm(df.iterrows(), total=len(df)):
# Filter to objects in the same image as your row
o = objects_df[objects_df['image_path'] == row['image_path']]
# Get value counts of object_name
object_counts = o['object_name'].value_counts()
output_string = ", ".join([f"{count}x {object_name}" for object_name, count in object_counts.items()])
object_texts.append({
'image_path': row['image_path'],
'Objects': output_string
})| Unnamed: 0 | ID | Time of Posting | Type of Content | video_url | image_url | Username | Video Length (s) | Expiration | Caption | Is Verified | Stickers | Accessibility Caption | Attribution URL | image_path | image | OCR | Objects | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2125373886060513565_1484534097 | 2019-09-04 08:05:27 | Image | NaN | NaN | afd.bund | NaN | 2019-09-05 08:05:27 | NaN | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537388606051... | /content/media/images/afd.bund/212537388606051... | FACEBOOK\nAfD\nf\nSwipe up\nund werde Fan! | |
| 1 | 2 | 2125374701022077222_1484534097 | 2019-09-04 08:07:04 | Image | NaN | NaN | afd.bund | NaN | 2019-09-05 08:07:04 | NaN | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537470102207... | /content/media/images/afd.bund/212537470102207... | YOUTUBE\nAfD\nSwipe up\nund abonniere uns! | |
| 2 | 3 | 2490851226217175299_1484534097 | 2021-01-20 14:23:30 | Image | NaN | NaN | afd.bund | NaN | 2021-01-21 14:23:30 | NaN | True | [] | Photo by Alternative für Deutschland on Januar... | NaN | /content/media/images/afd.bund/249085122621717... | /content/media/images/afd.bund/249085122621717... | TELEGRAM\nAfD\nSwipe up\nund folge uns! | |
| 3 | 4 | 2600840011884997131_1484534097 | 2021-06-21 08:31:45 | Image | NaN | NaN | afd.bund | NaN | 2021-06-22 08:31:45 | NaN | True | [] | Photo by Alternative für Deutschland on June 2... | NaN | /content/media/images/afd.bund/260084001188499... | /content/media/images/afd.bund/260084001188499... | Pol\nBeih | 3x Person, 1x Chair, 1x Table, 1x Picture frame |
| 4 | 5 | 2600852794831609459_1484534097 | 2021-06-21 08:57:09 | Image | NaN | NaN | afd.bund | NaN | 2021-06-22 08:57:09 | NaN | True | [] | Photo by Alternative für Deutschland in Berlin... | NaN | /content/media/images/afd.bund/260085279483160... | /content/media/images/afd.bund/260085279483160... | BERLIN, GERMANY\n2160 25.000\nMON 422 150M\nA0... | 4x Person, 1x Furniture, 1x Television |
Ensemble Klassifikation
Now we’re ready for the ensemble classification. My current version of this approach is highly experimental – evaluations and related work are still missing.
The idea behind our ensemble approach here is to provide the GPT model with Captions, Objects, and OCR detected and generated by different models. The final classification using the GPT prompt below relies solely on the outputs of the previous models. In other words: The final classification takes places without the actual image.
The results in my informal experiments appeared more consistent in contrast to CLIP classification. Yet, as the example below shows, they are not perfect either. The results using GPT-3.5 were insufficient, I suggest to use GPT-4 here!
system_prompt = """
**Assignment**: Leverage your expertise in political communication image analysis to classify images from the 2021 German federal election campaign found on Instagram. Ensure your analysis incorporates all pertinent information sources and optimally utilizes your adept understanding of the subtleties and nuances in political images. To do this, you must carefully analyze all available information: AI generated image captions, the objects identified in the image (including people), and the OCR text.
**Objective**:
Accurately classify each image into exactly one of the following categories. Ensure that it is as close-fitting to the image content as possible. Classify to accurately reflect the subtle political and communicative undercurrents in the images by assiduously considering all available data points.
**Image Categories**
1. Campaign Activities: This category includes images related to political rallies, public addresses, campaign promotions, and other activities directly related to the campaigning process.
2. Public Engagement: This category encompasses images that depict politicians interacting with the public, engaging in discussions, or participating in public events.
3. Traditional Media Campaigning: This category includes images related to politicians' appearances on television shows, in newspapers, and other traditional media outlets.
4. Digital and Social Media Campaigning: This category includes images related to online campaigning, social media engagement, digital advertisements, and politicians' presence on digital platforms.
5. Campaign Materials and Signage: This category includes images of campaign posters, signage, slogans, and other promotional materials used in political campaigns.
6. Politician Portrayals: This category includes images that focus on individual politicians, including portraits, candid shots, and images depicting politicians in various settings or activities.
7. Issue-Based Messaging: This category includes images that focus on specific issues or causes, such as climate change advocacy, COVID-19 precautions, or policy discussions.
**Formatting**:
- Output should exclusively feature the image classification. Return "Other", if none of the above categories can be assigned.
"""Requirement already satisfied: openai in /usr/local/lib/python3.10/dist-packages (1.10.0)
Requirement already satisfied: gpt-cost-estimator in /usr/local/lib/python3.10/dist-packages (0.4)
Requirement already satisfied: backoff in /usr/local/lib/python3.10/dist-packages (2.2.1)
Requirement already satisfied: anyio<5,>=3.5.0 in /usr/local/lib/python3.10/dist-packages (from openai) (3.7.1)
Requirement already satisfied: distro<2,>=1.7.0 in /usr/lib/python3/dist-packages (from openai) (1.7.0)
Requirement already satisfied: httpx<1,>=0.23.0 in /usr/local/lib/python3.10/dist-packages (from openai) (0.26.0)
Requirement already satisfied: pydantic<3,>=1.9.0 in /usr/local/lib/python3.10/dist-packages (from openai) (1.10.14)
Requirement already satisfied: sniffio in /usr/local/lib/python3.10/dist-packages (from openai) (1.3.0)
Requirement already satisfied: tqdm>4 in /usr/local/lib/python3.10/dist-packages (from openai) (4.66.1)
Requirement already satisfied: typing-extensions<5,>=4.7 in /usr/local/lib/python3.10/dist-packages (from openai) (4.9.0)
Requirement already satisfied: tiktoken in /usr/local/lib/python3.10/dist-packages (from gpt-cost-estimator) (0.5.2)
Requirement already satisfied: lorem-text in /usr/local/lib/python3.10/dist-packages (from gpt-cost-estimator) (2.1)
Requirement already satisfied: idna>=2.8 in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (3.6)
Requirement already satisfied: exceptiongroup in /usr/local/lib/python3.10/dist-packages (from anyio<5,>=3.5.0->openai) (1.2.0)
Requirement already satisfied: certifi in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (2023.11.17)
Requirement already satisfied: httpcore==1.* in /usr/local/lib/python3.10/dist-packages (from httpx<1,>=0.23.0->openai) (1.0.2)
Requirement already satisfied: h11<0.15,>=0.13 in /usr/local/lib/python3.10/dist-packages (from httpcore==1.*->httpx<1,>=0.23.0->openai) (0.14.0)
Requirement already satisfied: Click>=7.0 in /usr/local/lib/python3.10/dist-packages (from lorem-text->gpt-cost-estimator) (8.1.7)
Requirement already satisfied: regex>=2022.1.18 in /usr/local/lib/python3.10/dist-packages (from tiktoken->gpt-cost-estimator) (2023.6.3)
Requirement already satisfied: requests>=2.26.0 in /usr/local/lib/python3.10/dist-packages (from tiktoken->gpt-cost-estimator) (2.31.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests>=2.26.0->tiktoken->gpt-cost-estimator) (3.3.2)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests>=2.26.0->tiktoken->gpt-cost-estimator) (2.0.7)import openai
from openai import OpenAI
from google.colab import userdata
import backoff
from gpt_cost_estimator import CostEstimator
api_key_name = "openai-lehrstuhl-api"
api_key = userdata.get(api_key_name)
# Initialize OpenAI using the key
client = OpenAI(
api_key=api_key
)
@CostEstimator()
def query_openai(model, temperature, messages, mock=True, completion_tokens=10):
return client.chat.completions.create(
model=model,
temperature=temperature,
messages=messages,
max_tokens=600)
# We define the run_request method to wrap it with the @backoff decorator
@backoff.on_exception(backoff.expo, (openai.RateLimitError, openai.APIError))
def run_request(system_prompt, user_prompt, model, mock):
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
return query_openai(
model=model,
temperature=0.0,
messages=messages,
mock=mock
)| Unnamed: 0.3 | Unnamed: 0.2 | Unnamed: 0.1 | Unnamed: 0 | ID | Time of Posting | Type of Content | video_url | image_url | Username | ... | Is Verified | Stickers | Accessibility Caption | Attribution URL | image_path | OCR | Objects | caption | Vertex Caption | Ensemble | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 2125373886060513565_1484534097 | 2019-09-04 08:05:27 | Image | NaN | NaN | afd.bund | ... | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537388606051... | FACEBOOK\nAfD\nf\nSwipe up\nund werde Fan! | NaN | a collage of a picture of a person flying a kite | an ad for facebook shows a drawing of a facebo... | Digital and Social Media Campaigning |
| 1 | 1 | 1 | 1 | 2 | 2125374701022077222_1484534097 | 2019-09-04 08:07:04 | Image | NaN | NaN | afd.bund | ... | True | [] | Photo by Alternative für Deutschland on Septem... | NaN | /content/media/images/afd.bund/212537470102207... | YOUTUBE\nAfD\nSwipe up\nund abonniere uns! | NaN | a poster of a man with a red face | an advertisement for youtube with a red backgr... | Digital and Social Media Campaigning |
| 2 | 2 | 2 | 2 | 3 | 2490851226217175299_1484534097 | 2021-01-20 14:23:30 | Image | NaN | NaN | afd.bund | ... | True | [] | Photo by Alternative für Deutschland on Januar... | NaN | /content/media/images/afd.bund/249085122621717... | TELEGRAM\nAfD\nSwipe up\nund folge uns! | NaN | a large blue and white photo of a plane | an advertisement for telegram with a blue back... | Digital and Social Media Campaigning |
| 3 | 3 | 3 | 3 | 4 | 2600840011884997131_1484534097 | 2021-06-21 08:31:45 | Image | NaN | NaN | afd.bund | ... | True | [] | Photo by Alternative für Deutschland on June 2... | NaN | /content/media/images/afd.bund/260084001188499... | Pol\nBeih | 3x Person, 1x Chair, 1x Table, 1x Picture frame | a woman sitting at a desk with a laptop | two women are sitting at a table talking to ea... | Public Engagement |
| 4 | 4 | 4 | 4 | 5 | 2600852794831609459_1484534097 | 2021-06-21 08:57:09 | Image | NaN | NaN | afd.bund | ... | True | [] | Photo by Alternative für Deutschland in Berlin... | NaN | /content/media/images/afd.bund/260085279483160... | BERLIN, GERMANY\n2160 25.000\nMON 422 150M\nA0... | 4x Person, 1x Furniture, 1x Television | a man sitting in front of a screen with a tv | a camera is recording a man sitting at a table... | Traditional Media Campaigning |
5 rows × 23 columns
from tqdm.auto import tqdm
import json
#@markdown Do you want to mock the OpenAI request (dry run) to calculate the estimated price?
MOCK = False # @param {type: "boolean"}
#@markdown Do you want to reset the cost estimation when running the query?
RESET_COST = True # @param {type: "boolean"}
#@markdown Do you want to run the request on a smaller sample of the whole data? (Useful for testing). Enter 0 to run on the whole dataset.
SAMPLE_SIZE = 0 # @param {type: "number", min: 0}
#@markdown Which model do you want to use?
MODEL = "gpt-4-1106-preview" # @param ["gpt-3.5-turbo-1106", "gpt-4-1106-preview", "gpt-4-0613"] {allow-input: true}
# Reset Estimates
CostEstimator.reset()
print("Reset Cost Estimation")
filtered_df = df.copy()
if SAMPLE_SIZE > 0:
filtered_df = filtered_df.sample(SAMPLE_SIZE)
classifications = []
for index, row in tqdm(filtered_df.iterrows(), total=len(filtered_df)):
try:
prompt_dict = {
'AI Caption': row['Vertex Caption'],
'Objects': row['Objects'],
'OCR': row['OCR']
}
prompt = json.dumps(prompt_dict)
response = run_request(system_prompt, prompt, MODEL, MOCK)
if not MOCK:
# Extract the response content
# Adjust the following line according to the structure of the response
r = response.choices[0].message.content
# Update the 'new_df' DataFrame
classifications.append({
'image_path': row['image_path'],
'Ensemble': r
})
except Exception as e:
print(f"An error occurred: {e}")
# Optionally, handle the error (e.g., by logging or by setting a default value)
print()Reset Cost EstimationCost: $0.0052 | Total: $0.8935| image_path | Ensemble | |
|---|---|---|
| 0 | /content/media/images/afd.bund/212537388606051... | Digital and Social Media Campaigning |
| 1 | /content/media/images/afd.bund/212537470102207... | Digital and Social Media Campaigning |
| 2 | /content/media/images/afd.bund/249085122621717... | Digital and Social Media Campaigning |
| 3 | /content/media/images/afd.bund/260084001188499... | Public Engagement |
| 4 | /content/media/images/afd.bund/260085279483160... | Traditional Media Campaigning |
| ... | ... | ... |
| 175 | /content/media/images/afd.bund/270307816811455... | Traditional Media Campaigning |
| 176 | /content/media/images/afd.bund/270308716101492... | Digital and Social Media Campaigning |
| 177 | /content/media/images/afd.bund/273087156360183... | Issue-Based Messaging |
| 178 | /content/media/images/afd.bund/273802362693505... | Campaign Materials and Signage |
| 179 | /content/media/images/afd.bund/278425114235569... | Digital and Social Media Campaigning |
180 rows × 2 columns
import pandas as pd
from IPython.display import display, Image
import random
def display_random_image_and_classification(df):
# Select a random row from the DataFrame
filtered_df = df[~pd.isna(df['Ensemble'])]
random_row = filtered_df.sample(1).iloc[0]
# Get the image path and classification from the row
image_path = random_row['image_path'] # Replace 'image_path' with the actual column name
# Display the image
display(Image(filename=image_path))
# Display the classification
print(f"Caption: {random_row['Vertex Caption']}")
print(f"OCR: {random_row['OCR']}")
print(f"Objects: {random_row['Objects']}")
print(f"Ensemble Classification: {random_row['Ensemble']}")
# Call the function to display an image and its classification
display_random_image_and_classification(df)Conclusion
In wrapping up this chapter, we see that ensemble classification offers a new perspective in analyzing visual social media. By combining Captions, Objects, and OCR, we create a more versatile tool for image classification with GPT models, especially useful when we can’t rely on direct image analysis. A key advantage of this approach is its flexibility. You can adjust the focus to suit your project’s needs, whether that’s on text with OCR or objects in the image.
Reuse
Citation
BibTeX citation:
@online{achmann-denkler2024,
author = {Achmann-Denkler, Michael},
title = {Ensemble {Image} {Classification}},
date = {2024-01-22},
url = {https://social-media-lab.net/image-analysis/ensemble.html},
doi = {10.5281/zenodo.10039756},
langid = {en}
}
For attribution, please cite this work as:
Achmann-Denkler, Michael. 2024. “Ensemble Image
Classification.” January 22, 2024. https://doi.org/10.5281/zenodo.10039756.