The setup for visual annotation projects (as well as videos and audio), includes an additional step: We need to store our media files somewhere accessible for labelstudio. My choice is Google Cloud Buckets, as the setup is (relatively) easy. Additionally, the coupons provided by Google are sufficient to pay for the expenses of hosting our images on the Google Cloud. The manual below is almost identical to my Medium story “How to Accelerate your Annotation Process for Visual Social Media Analysis with Label Studio”. Please follow the steps outline in the story (first paragraphs and screenshots) to obtain your cloud credential json file. Alternatively use the credentials provided on GRIPS for our course.
Cloud Bucket Setup & IAM
Important in contrast to the medium story, one additional step is necessary as pointed out by the Label Studio manual: we still need to configure the CORS of our bucket.
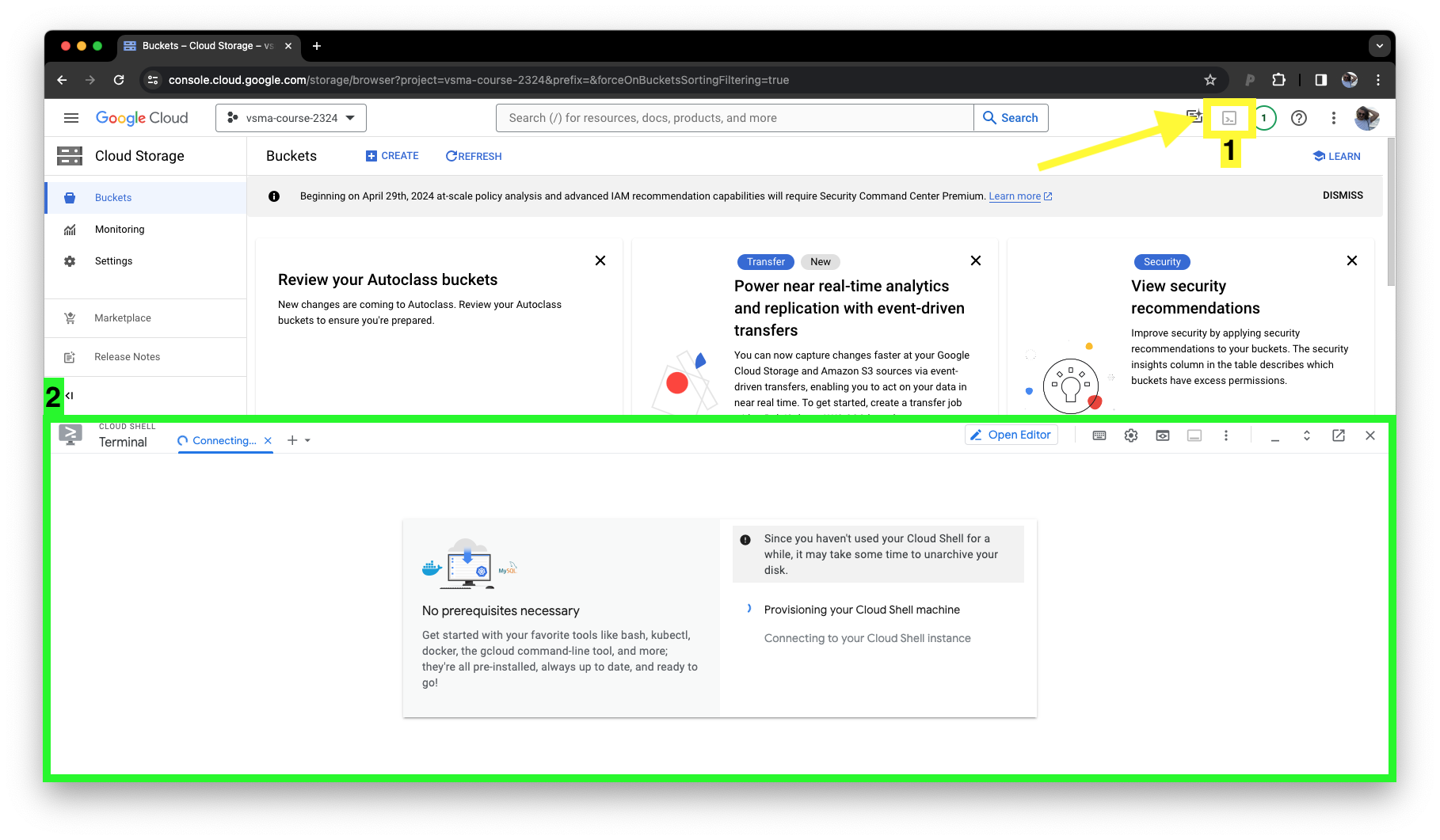
Open any page inside your cloud project. Click on the right hand terminal symbol (yellow, 1) first. The terminal opens and takes a moment to spin up. In the meantime visit the Label Studio manual to copy the values.
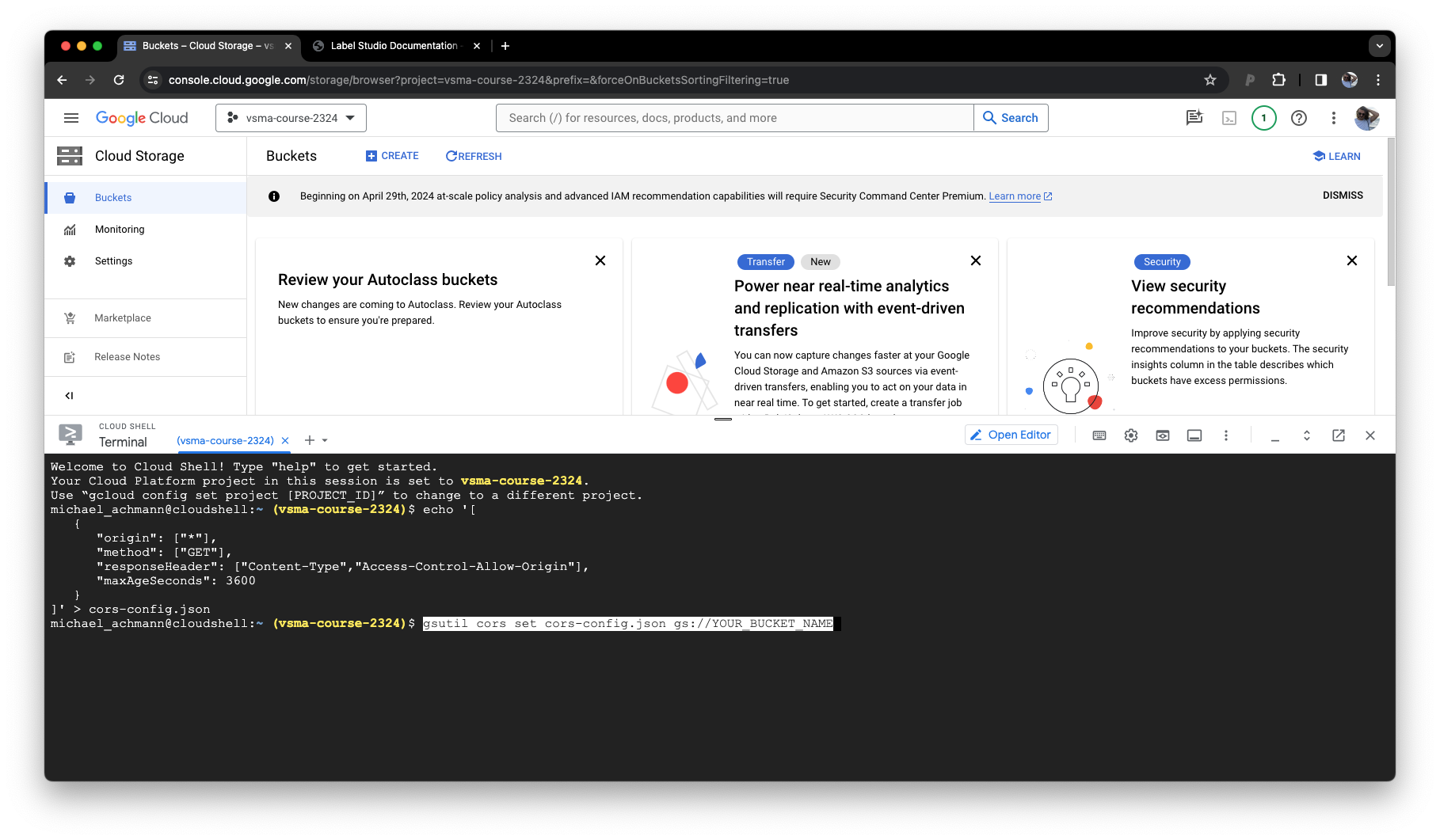
Copy the values from the documentation into the terminal. Hit Enter. Replace the bucketname with yours in the second step.
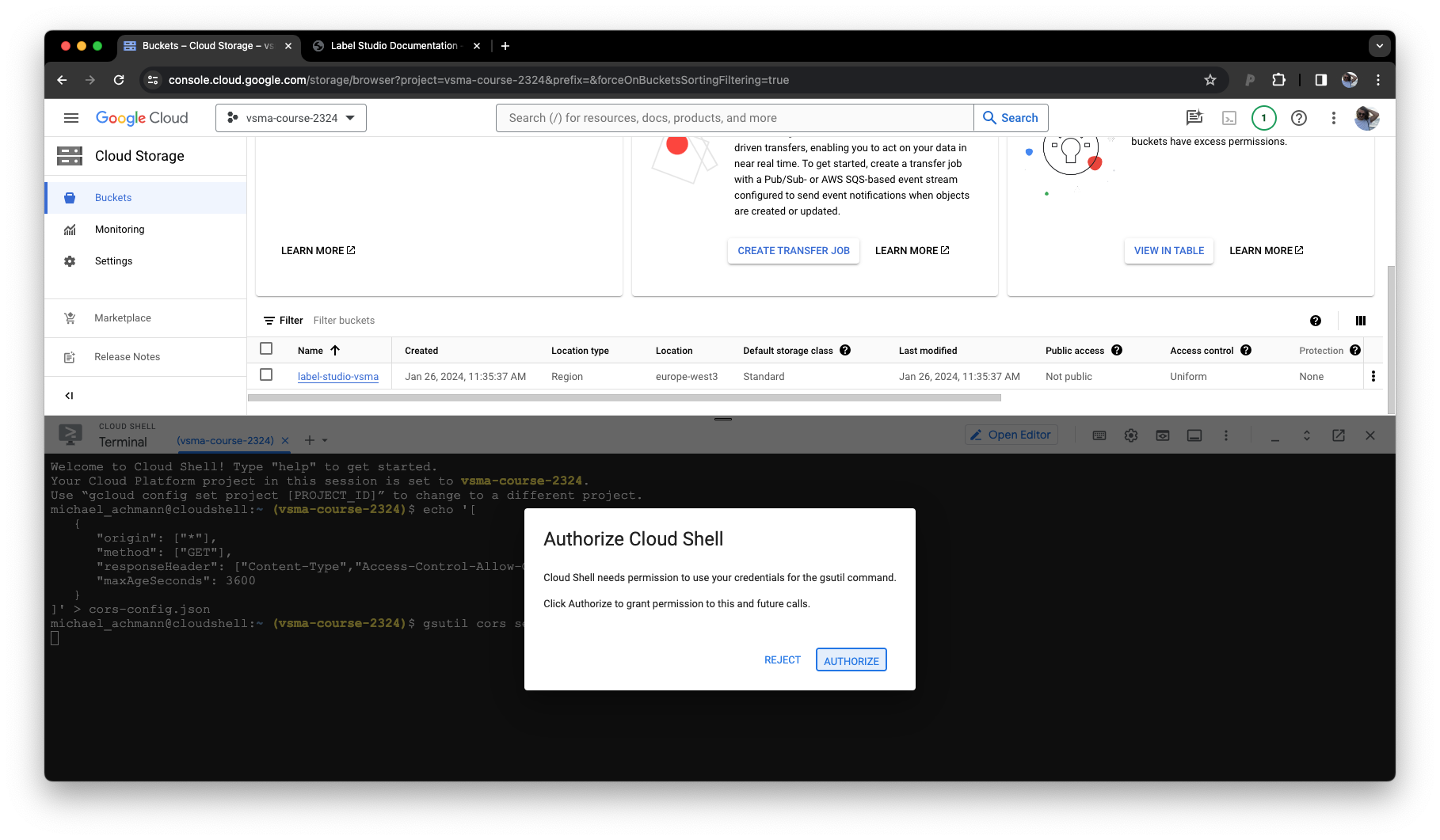
Grant acces. Wait a few seconds. Your images are now accessible from Label Studio
Creating the Annotation Project
First lets install the packages:
!pip -q install label-studio-sdk gcloud
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━0.0/454.4 kB? eta -:--:--━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━━348.2/454.4 kB10.2 MB/s eta 0:00:01━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━454.4/454.4 kB9.5 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Building wheel for gcloud (setup.py) ... done
Next, setup Google Cloud. Please specify the file path for the credentials file in order to upload images to google cloud bucket (provided via GRIPS or your own).
We’re using the naming convention {cloud-bucket}/{username}/{id}.jpg. The naming convention is important, as we will use it later on to map the manual and computational annotations into one dataframe. (See Identifier in the text annotation project).
Before creating the LabelStudio project you will need to define your labelling interface. Once the project is set up you will only be able to edit the interface in LabelStudio.
Do you want add codes (Classification) to the images? Please name your coding instance and add options. By running this cell multiple times you’re able to add multiple variables (not recommended)
Add the variable name to coding_name, the checkbox labels in coding_values, and define whether to expect single choice or multiple choice input for this variable in coding_choice.
#@title ### Codes#@markdown Do you want add codes (Classification) to the images? Please name your coding instance and add options. <br/> **By running this cell multiple times you're able to add multiple variables (not recommended)**coding_name ="Sentiment"#@param {type:"string"}coding_values ="Positive,Neutral,Negative"#@param {type:"string"}coding_choice ="single"#@param ["single", "multiple"]coding_interface ='<Header value="{}" /><Choices name="{}" choice="{}" toName="Image">'.format(coding_name, coding_name,coding_choice)for value in coding_values.split(","): value = value.strip() coding_interface +='<Choice value="{}" />'.format(value)coding_interface +="</Choices>"interface += coding_interfaceprint("Added {}".format(coding_name))
Added Sentiment
Don’t forget to run the next line! It closes the interface XML!
interface +=""" </View> </View> """
Project Upload
This final step creates a LabelStudio project and configures the interface. Define a project_name, and identifier_column. Additionally, you may define a sample_percentage for sampling, we start with \(30\%\). When working with the Open Source version of Label Studio we need to create on project per annotator, enter the number of annotators in num_copies to create multiple copies at once.
from label_studio_sdk import Clientimport contextlibimport ioproject_name ="vSMA Image Test 1"#@param {type: "string"}identifier_column ="ID"#@param {type: "string"}#@markdown Percentage for drawing a sample to annotate, e.g. 30%sample_percentage =30#@param {type: "number", min:0, max:100}#@markdown Number of project copies. **Start testing with 1!**num_copies =1#@param {type: "number", min:0, max:3}sample_size =round(len(df) * (sample_percentage /100))ls = Client(url=labelstudio_url, api_key=labelstudio_key)# Import all tasksdf_tasks = df[[identifier_column, 'Image']]df_tasks = df_tasks.sample(sample_size)df_tasks = df_tasks.fillna("")for i inrange(0, num_copies): project_name =f"{project_name} #{i}"# Create the project project = ls.start_project( title=project_name, label_config=interface, sampling="Uniform sampling" )# Configure Cloud Storage (in order to be able to view the images) project.connect_google_import_storage(bucket=gcloud_bucket, google_application_credentials=json.dumps(credentials_dict))with contextlib.redirect_stdout(io.StringIO()): project.import_tasks( df_tasks.to_dict('records') )print(f"All done, created project #{i}! Visit {labelstudio_url}/projects/{project.id}/ and get started labelling!")
All done, created project #0! Visit https://label2.digitalhumanities.io/projects/71/ and get started labelling!
The interface created using the notebook above is very basic. Refer to this manual for creating sophisticated labelling interfaces. In contrast to textual annotations, we need to add the <Image name="Image" value="$Image"/> tag as an object to be annotated. The $Image variable should be equal to the column name where we add the Google Cloud Bucket URL in the dataframe (see above).
Conclusion
This article provided additional information to automatically create image annotation projects. The provided notebook may easily be modified to handle videos and audio files. The code to upload the media files to the cloud bucket would stay the same, we’d have to modify the filenames (for the proper suffixes), and change the labelling interface to be compatible with video or audio files (see Label Studio documentation). This article is an alternative path of my annotation manual, which offers more background information on human annotations.